Agent Behavior Monitoring
Run real-time checks on your agents' behavior in production.
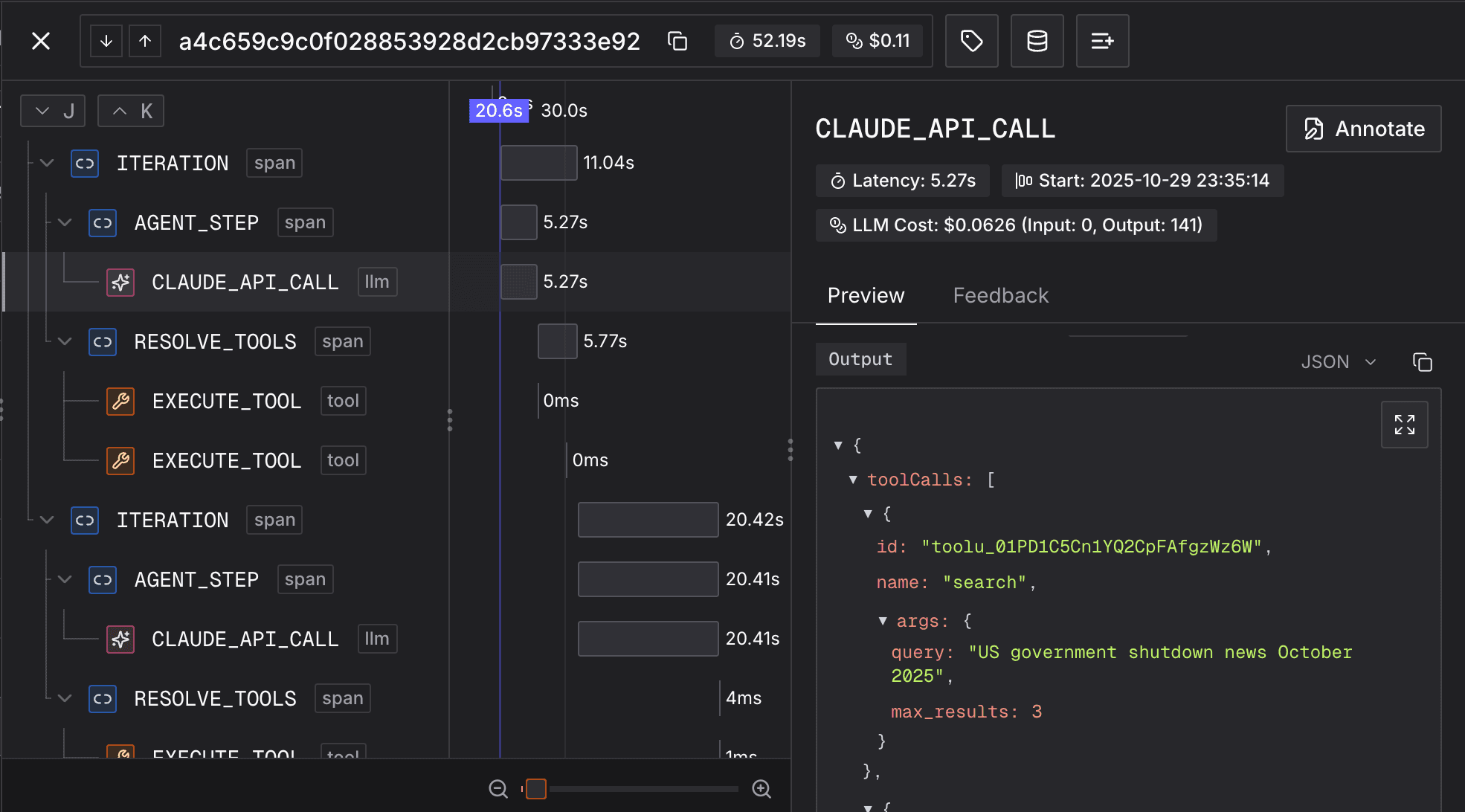
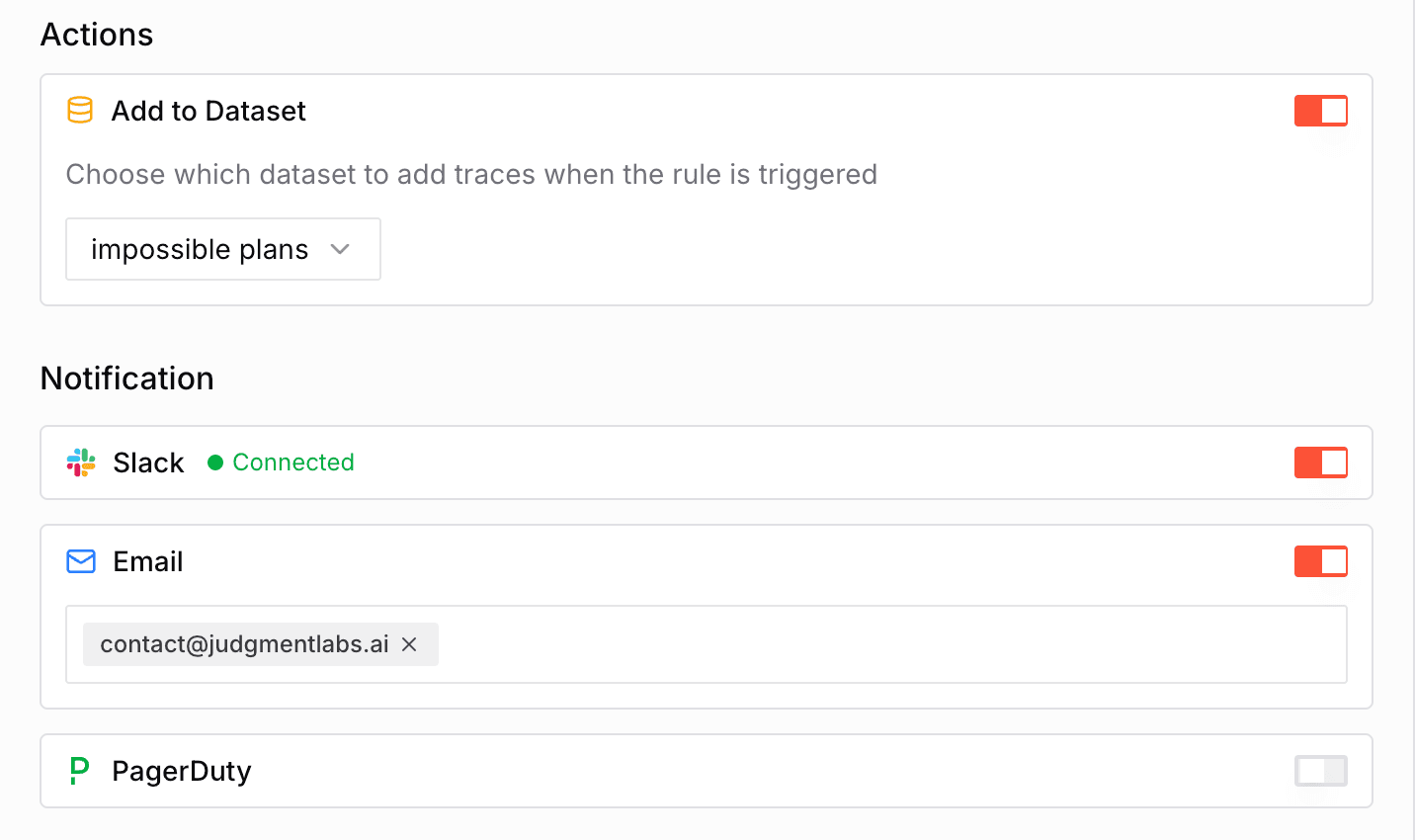
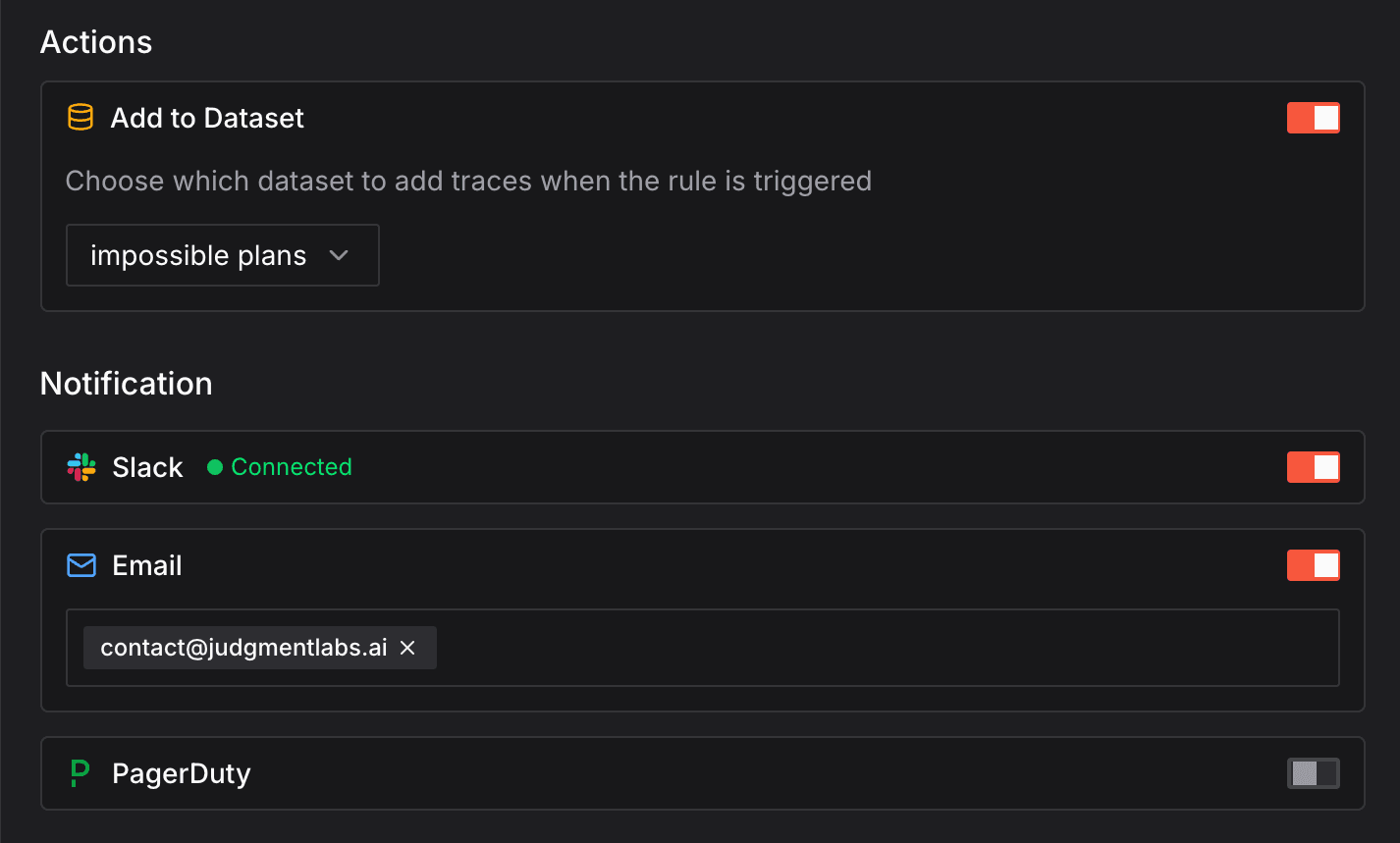
Agent behavior monitoring provides comprehensive observability into your production agents. By combining tracing, behaviors, and alerting, you can track what your agents do, detect when they misbehave, and identify behavioral trends - all in real-time.



Next Steps
Explore each component of agent behavior monitoring in detail:
- Tracing - Deep dive into OpenTelemetry-based tracing, distributed tracing, and advanced instrumentation
- Behaviors - Set up automated behavior classification and pattern analysis
- Automations and Alerts - Configure sophisticated alerting automations with frequency thresholds, cooldowns, and multi-channel notifications