Agent Judges
Use natural language rubrics to evaluate agent behavior with agent-based evaluation.
Agent Judges (PromptScorer in the SDK) use natural language rubrics to evaluate agent behavior using the Judgment agent harness.
Create an Agent Judge


Create your judge
Click New Judge. Choose the type of judge (binary, classification, or score).
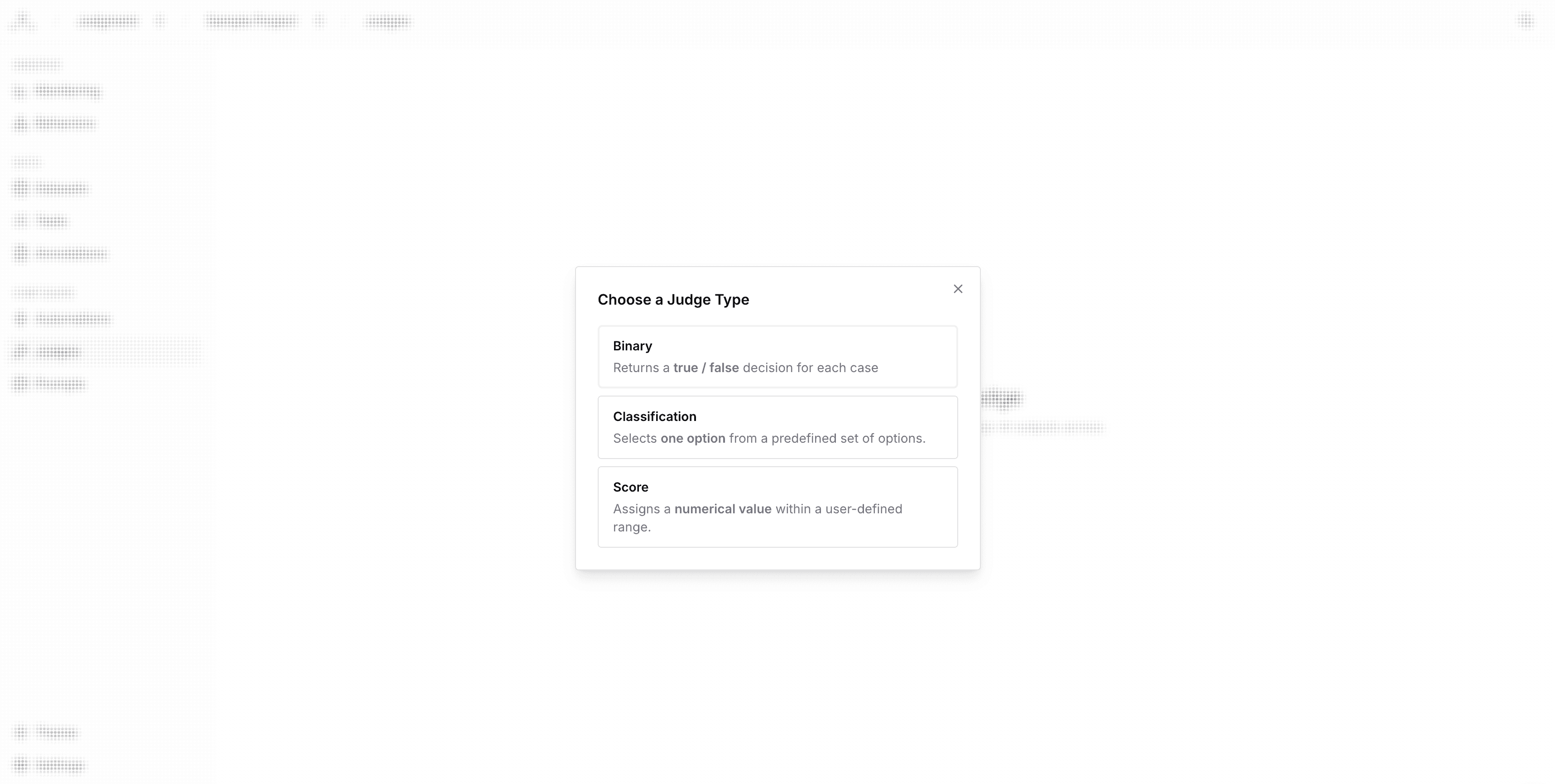
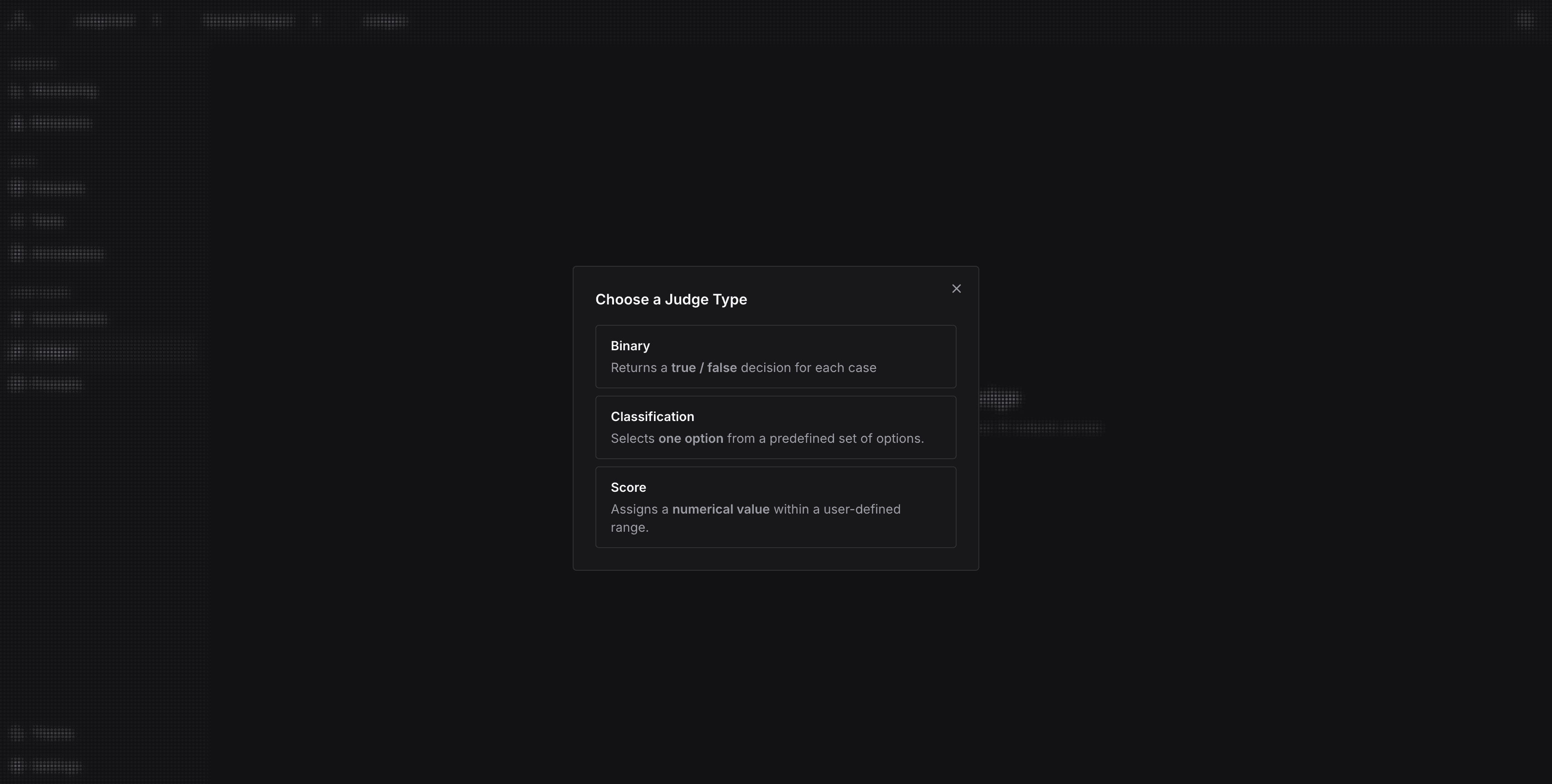
Then, click Next to configure the judge.
Configure the judge
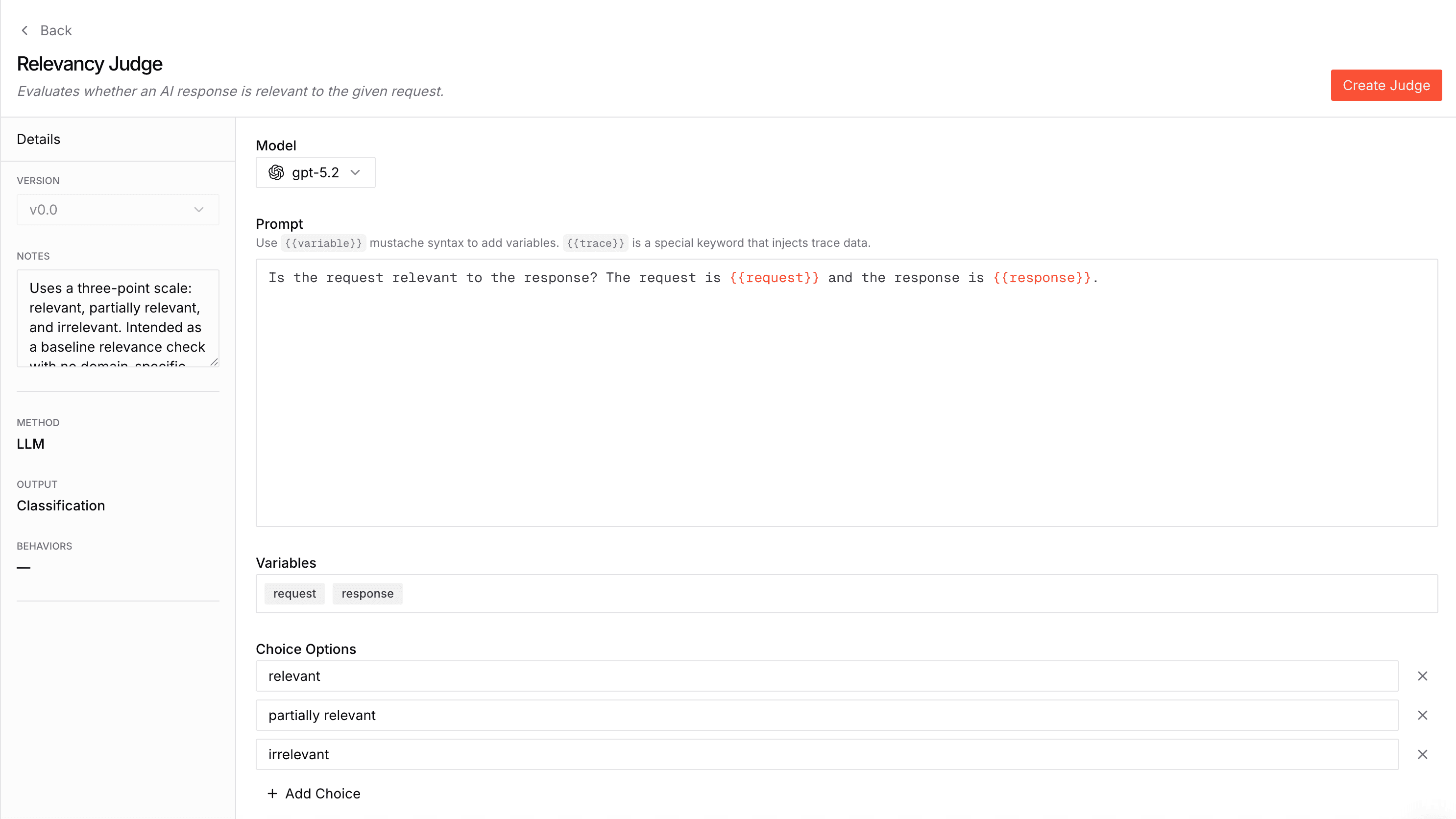
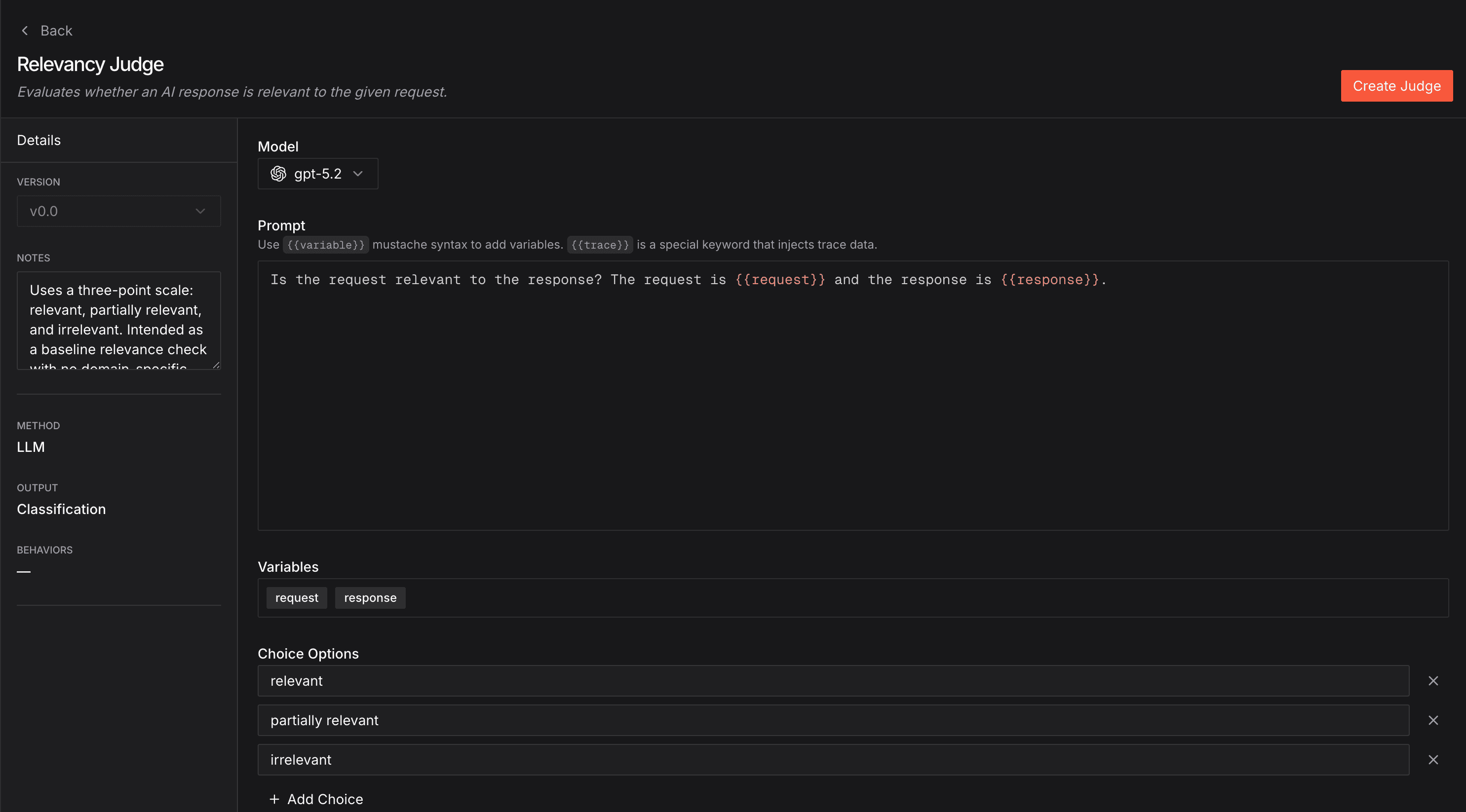
Name the judge and feel free to add a description.
Judges are versioned, each version has the following configuration options:
Model: Choose your judge model
Prompt: Define your evaluation criteria (supports {{ mustache template }} variables)
Choices: (for categorical judges): Choices that the judge can pick from
Notes: Notes about the specific version
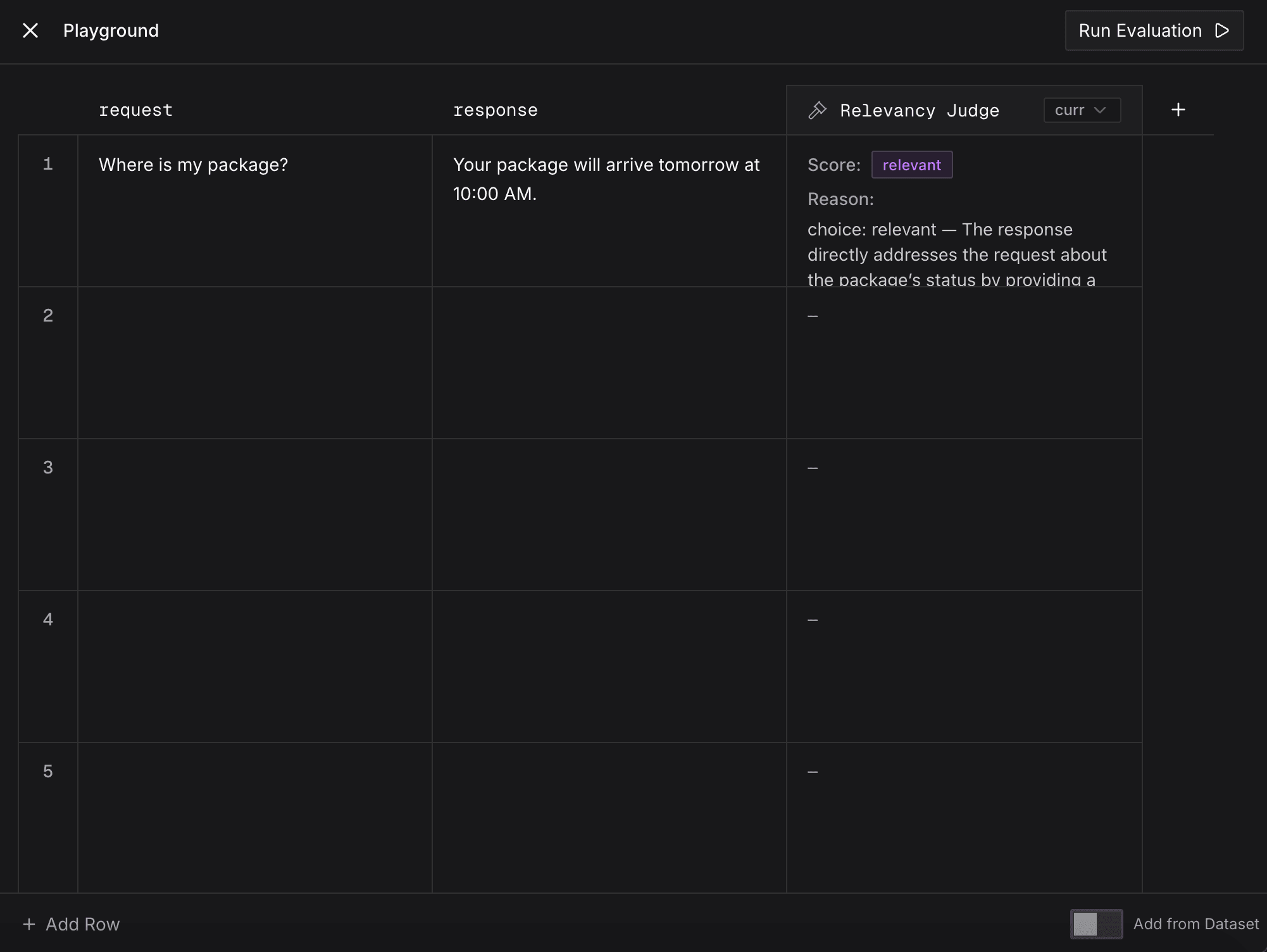
Test the judge
Test your Agent Judge with custom inputs from the Playground tab in the right-side panel. You can enter these custom inputs manually or add from a dataset. In addition, you can also add other judges or different versions of the same judge.
Then click Run.
You'll see the judge's score and reasoning for each judge in the output.

Manage Agent Judges from the SDK
You can also create and update Agent Judges programmatically from the SDK — client.agent_judges in Python, client.agentJudges in TypeScript. This is useful for codifying judge rubrics alongside your agent code or rolling out rubric changes through your existing review process.
Create a judge
from judgeval import Judgeval
client = Judgeval(project_name="default_project")
judge = client.agent_judges.create(
name="helpfulness",
prompt="Score the assistant's helpfulness from 0 to 1.",
model="gpt-5.2",
score_type="numeric",
)import { Judgeval } from "judgeval";
const client = await Judgeval.create({ projectName: "default_project" });
const judge = await client.agentJudges.create({
name: "helpfulness",
prompt: "Score the assistant's helpfulness from 0 to 1.",
model: "gpt-5.2",
scoreType: "numeric",
});The score type is one of "numeric", "binary", or "categorical". For categorical judges, pass categories (e.g. [{"name": "good", "description": "..."}, ...]); for numeric judges, the min and max score default to 0 and 1.
Update a judge
Updating any of prompt, model, categories, min_score, or max_score writes a new version of the judge. By default the server bumps the latest version's minor by 1 — matching the UI's default "save" behaviour.
client.agent_judges.update(
judge_id=judge.judge_id,
prompt="Updated rubric prompt.",
)Pass source_major_version / source_minor_version to copy unspecified fields from a specific past version, or target_major_version / target_minor_version to write to a specific version slot.
await client.agentJudges.update({
judgeId: judge.judgeId,
prompt: "Updated rubric prompt.",
});Pass sourceMajorVersion / sourceMinorVersion to copy unspecified fields from a specific past version, or targetMajorVersion / targetMinorVersion to write to a specific version slot.
Template Variables
Agent Judge prompts support {{ mustache }} variables. How you use them depends on whether you're running online or offline.
Online judges don't need variables. When a trace is ingested, the judge automatically receives full context — span inputs, outputs, tool calls, and LLM calls — so the rubric can reference your agent's behavior directly without any placeholders.
Offline testing is where variables become useful. A dataset declares typed fields in its schema (e.g. golden_output, expected_category), and each example supplies values for them. Those fields map to {{ variables }} in your judge prompt, letting the judge compare the agent's actual trace output against the expected value. A judge is only compatible with a dataset when every placeholder in its prompt is a declared field in that dataset's schema.
For most online monitoring use cases, skip variables entirely — the judge already knows what your agent did.
Next Steps
- Monitor Agent Behavior in Production - Deploy your judges for real-time agent evaluation.
- Iterate with the Judgment Agent - Ask the in-product AI agent to score real traces and propose sharper rubrics with reviewable diffs.