Introduction
Learn how to use all features of Judgment's real-time tracing module.
Quickstarts
Tracing
To get started with tracing, you can decorate your functions with the @judgment.observe() decorator.
You can also capture LLM generation telemetry by using wrap() function around your LLM Client.
We currently support wrapping any of the following clients:
- OpenAI, AsyncOpenAI
- Anthropic, AsyncAnthropic
- genai.Client, genai.client.AsyncClient
- Together, AsyncTogether
- Groq, AsyncGroq
from judgeval.tracer import Tracer, wrap
from openai import OpenAI
client = wrap(OpenAI()) # tracks all LLM calls
judgment = Tracer(project_name="default_project")
@judgment.observe(span_type="tool")
def format_question(question: str) -> str:
# dummy tool
return f"Question : {question}"
@judgment.observe(span_type="function")
def run_agent(prompt: str) -> str:
task = format_question(prompt)
response = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": task}]
)
return response.choices[0].message.content
run_agent("What is the capital of the United States?")You will see your trace unfold live in the UI, with each span and event appearing in real time as the operation executes. Check your terminal for a link to view the trace!
Integrate With Online evals
You can run evals on your traces with any of judgeval's built-in scorers in real-time, enabling you to
flag and alert on regressions in production.
To run an online eval, it takes one line of code with the async_evaluate() function.
In this example, we'll use the AnswerRelevancyScorer to evaluate the relevance of the agent's response to the user's query.
from judgeval.common.tracer import Tracer, wrap
from judgeval.scorers import AnswerRelevancyScorer
from openai import OpenAI
client = wrap(OpenAI())
judgment = Tracer(project_name="default_project")
@judgment.observe(span_type="tool")
def format_question(question: str) -> str:
# dummy tool
return f"Question : {question}"
@judgment.observe(span_type="function")
def run_agent(prompt: str) -> str:
task = format_question(prompt)
response = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": task}]
)
answer = response.choices[0].message.content
judgment.async_evaluate(
scorer=AnswerRelevancyScorer(threshold=0.5),
example = Example(input=task, actual_output=answer),
model="gpt-4.1"
)
print("Online evaluation submitted.")
return answer
run_agent("What is the capital of the United States?")You should see the online eval results on the Judgment platform shortly after the trace is recorded. Evals can take time to execute, so they may appear slightly delayed on the UI. Once the eval is complete, you should see it attached to your trace like this:
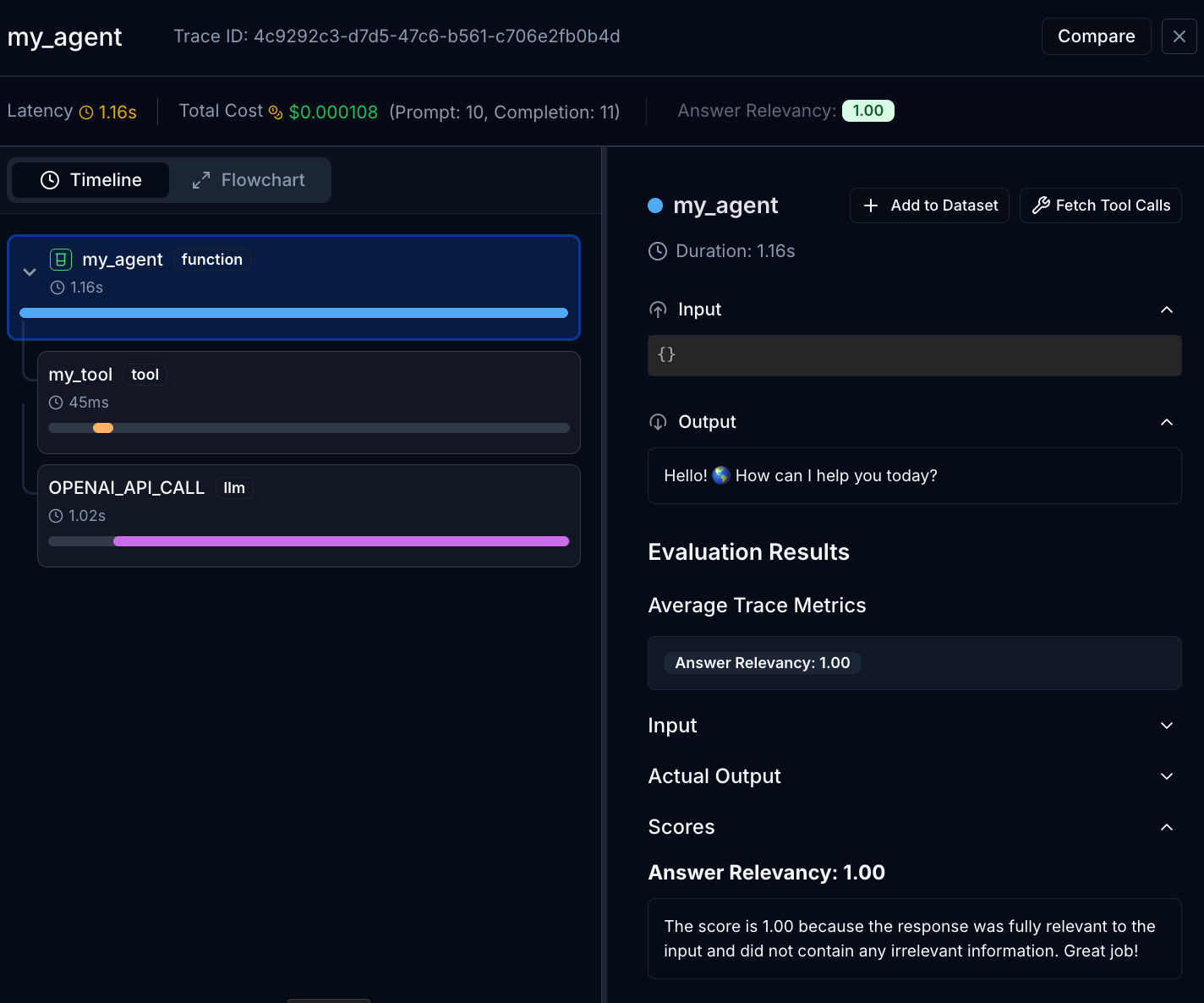
Trace Your Agents
When working with multi-agent systems, it can be useful to see very easily which agents were calling methods throughout a trace.
In order to aid with this, you can also decorate a class with the @judgment.agent() decorator.
from judgeval.common.tracer import Tracer
judgment = Tracer(project_name="default_project")
# judgment.agent() will identify the agent based on the class name
# if no identifier is provided.
@judgment.agent()
class OrchestratorAgent:
@judgment.observe(span_type="function")
def send_messages(self):
alice = SimpleAgent("Alice") # agent will be identified as "Alice"
bob = SimpleAgent("Bob")
alice.send_message("Hello Bob, how are you?")
bob.send_message("I'm good Alice, thanks for asking!")
# judgment.agent() specifies that the agents will be
# identified based on their "name" attribute.
@judgment.agent(identifier="name")
class SimpleAgent:
def __init__(self, name: str):
self.name = name
@judgment.observe(span_type="tool")
def send_message(self, content: str) -> None:
return f"Message sent with content: {content}"
@judgment.observe(span_type="function")
def main():
orchestrator = OrchestratorAgent()
orchestrator.send_messages()
main()The trace should show up in the Judgment platform clearly indicating which agent called which method:
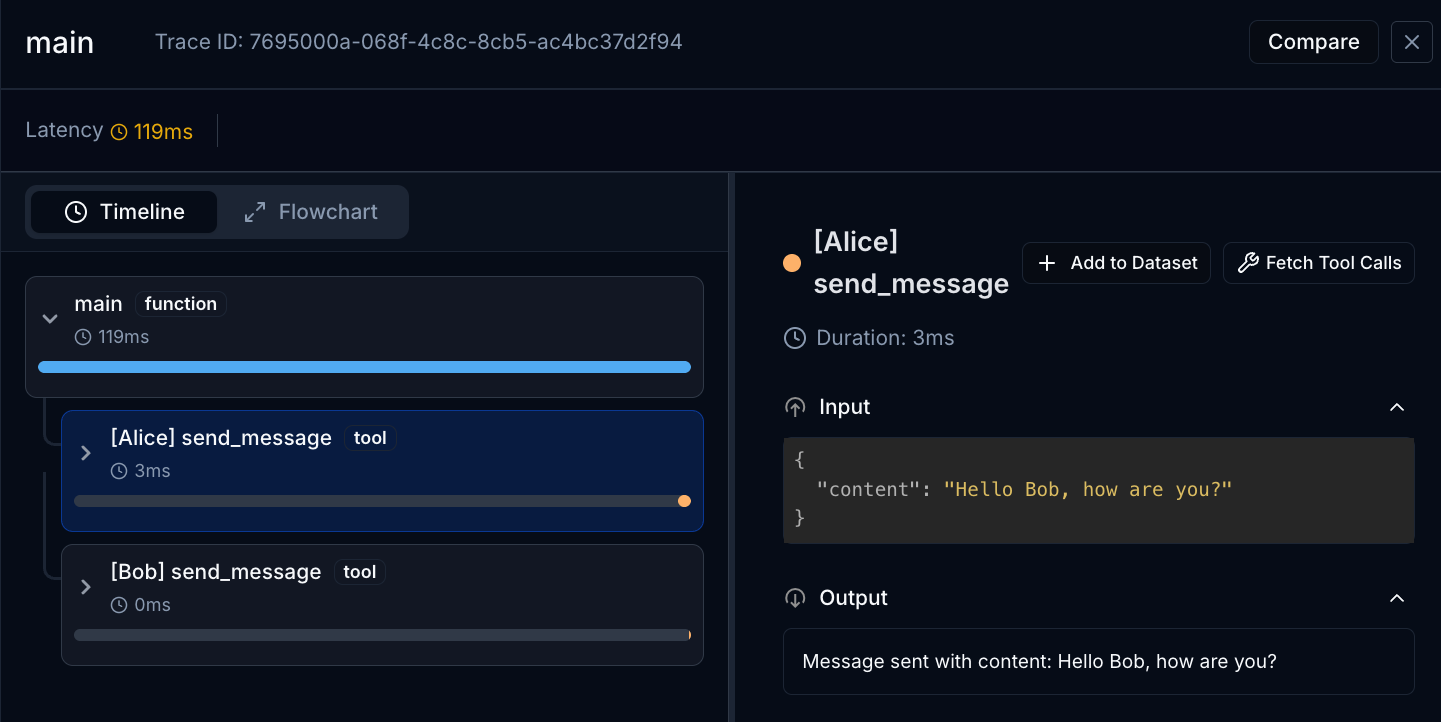
After running this trace, you can export the complete agent environment data from the Judgment platform:
- Navigate to your trace in the platform
- Click the "Fetch Tool Calls" button in the trace view
- All tool calls by agent: Which specific agent made each tool call with full attribution
- Input/environment reactions: How each agent responded to environmental inputs and state changes
- Trajectories of entire trace: Complete execution path showing agent decision flows and interaction patterns
- Added metadata: All custom metadata set via
judgment.set_metadata()calls
The exported data will include comprehensive information about each agent's statea and behavior, making it easy to analyze multi-agent interactions, debug complex scenarios, and optimize agents for your environment.
Toggling Monitoring
If your setup requires you to toggle monitoring in production-level environments, you can disable monitoring by:
- Setting the
JUDGMENT_MONITORINGenvironment variable tofalse(Disables tracing)
export JUDGMENT_MONITORING=false- Setting the
JUDGMENT_EVALUATIONSenvironment variable tofalse(Disables async_evaluates)
export JUDGMENT_EVALUATIONS=false