Evaluating AI Agents
Understanding AI Agents, and why Evaluation is Essential
AI Agent Evaluation
Developing AI Agents that work requires deep levels of observation and iteration through all levels of the agent. A faulty response upstream can sometimes lead to faulty responses downstream, which can often be non-deterministic and not show up all the time. Attempting to debug a multi-stage process applying many LLM calls using the terminal is near impossible.
The agent can fail at each step in the process: routing, memory (retrieval and tool-specific), and tool execution.
Tool Calling
Judgment is designed for agent builders that use tool calling. When agents call a tool, there are several places where the workflow may fail, specifically tool selection, parameter choice, and the tool execution itself, particularly if the tool is another LLM call.
Tool Calling Accuracy
When agent builders iterate on agents using Judgeval, they can use metrics such as tool parameter validation and tool ordering to make sure the agent processes are successful, as well as the outputs. For more information about tool-order specific metrics, check out the agent scorers page.
Router
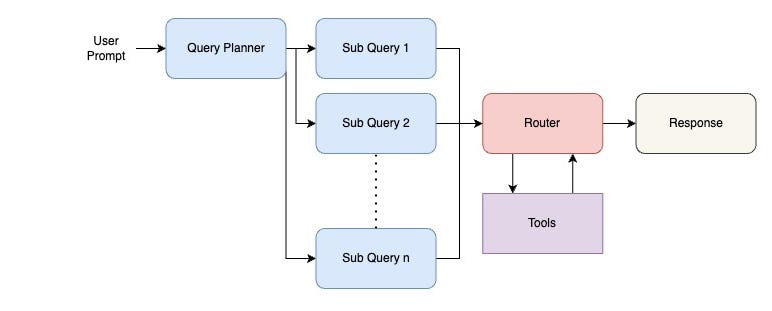
We can think of the router of the LLM as its "brain," responsible for overall decision making through the "thinking" process. When an agent receives a request, a routing LLM processes the request and determines the course of action. In each specific workflow, the tools available to the agent and the pathing varies, however, it can fail at each step. To evaluate a router, we must ensure that it chooses the correct next node and provides the correct parameters.
Judgment provides the execution order and derailment scorers for evaluation of the router, ensuring the agent remains on task and selects the correct tool for the task.
Memory
In a similar way to humans, agents store memory in both long and short term storage, through the retrieval context and agent specific memory. A RAG system contains retrieval memory from a database or larger context, while a more complicated agent stores information from previous runs, task specific rules and guidelines that the agent must follow.