---
You are an expert in helping users integrate Judgment with their codebase. When you are helping someone integrate Judgment tracing or evaluations with their agents/workflows, refer to this file.
---
# Agent Rules
URL: /documentation/agent-rules
Integrate Judgment seamlessly with Claude Code and Cursor
***
title: "Agent Rules"
description: "Integrate Judgment seamlessly with Claude Code and Cursor"
------------------------------------------------------------------------
Add Judgment context to your AI code editor so it can help you implement tracing, evaluations, and monitoring correctly.
## Quick Setup
**Add to global rules (recommended):**
```bash
curl https://docs.judgmentlabs.ai/agent-rules.md -o ~/.claude/CLAUDE.md
```
**Or add to project-specific rules:**
```bash
curl https://docs.judgmentlabs.ai/agent-rules.md -o CLAUDE.md
```
```bash
mkdir -p .cursor/rules
curl https://docs.judgmentlabs.ai/agent-rules.md -o .cursor/rules/judgment.mdc
```
After adding rules, your AI assistant will understand Judgment's APIs and best practices.
## What This Enables
Your AI code editor will automatically:
* Use correct Judgment SDK patterns
* Implement tracing decorators properly
* Configure evaluations with appropriate scorers
* Follow multi-agent system conventions
## Manual Setup
[View the full rules file](/agent-rules.md) to copy and paste manually.
# Security & Compliance
URL: /documentation/compliance
***
## title: Security & Compliance
At Judgment Labs, we take security and compliance seriously. We maintain rigorous standards to protect our customers' data and ensure the highest level of service reliability.
## SOC 2 Compliance
### Type 2 Certification
We have successfully completed our SOC 2 Type 2 audit, demonstrating our commitment to meeting rigorous security, availability, and confidentiality standards. This comprehensive certification validates the operational effectiveness of our security controls over an extended period, ensuring consistent adherence to security protocols.
Our SOC 2 Type 2 compliance covers the following trust service criteria:
* **Security**: Protection of system resources against unauthorized access
* **Availability**: System accessibility for operation and use as committed
* **Confidentiality**: Protection of confidential information as committed
View our [SOC 2 Type 2 Report](https://app.delve.co/judgment-labs) through our compliance portal.
## HIPAA Compliance
We maintain HIPAA compliance to ensure the security and privacy of protected health information (PHI). Our infrastructure and processes are designed to meet HIPAA's strict requirements for:
* Data encryption
* Access controls
* Audit logging
* Data backup and recovery
* Security incident handling
Access our [HIPAA Compliance Report](https://app.delve.co/judgment-labs) through our compliance portal. If you're working with healthcare data, please contact our team at [contact@judgmentlabs.ai](mailto:contact@judgmentlabs.ai) to discuss your specific compliance needs.
## Security Framework
We operate under a shared responsibility model where Judgment Labs secures:
* **Application Layer**: Secure coding practices, vulnerability management, and application-level controls
* **Platform Layer**: Infrastructure security, access controls, and monitoring
* **Data Protection**: Encryption at rest and in transit, secure data handling, and privacy controls
## Trust & Transparency
### Compliance Portal
All compliance documentation, certifications, and security reports are available through our dedicated [Trust Center](https://app.delve.co/judgment-labs). This portal provides:
* Current compliance certifications
* Security assessment reports
* Third-party audit documentation
* Data processing agreements
### Data Processing Agreement (DPA)
Our Data Processing Agreement outlines the specific terms and conditions for how we process and protect your data. The DPA covers:
* Data processing purposes and legal basis
* Data subject rights and obligations
* Security measures and incident response
* International data transfers
* Sub-processor agreements
Review our [Data Processing Agreement](https://app.delve.co/judgment-labs/dpa) for detailed terms and conditions regarding data processing activities.
### Contact Information
For security-related inquiries:
* **General Security Questions**: [contact@judgmentlabs.ai](mailto:contact@judgmentlabs.ai)
* **Compliance Documentation**: Request access through our [Trust Center](https://app.delve.co/judgment-labs)
* **HIPAA Inquiries**: For healthcare data requirements, contact [support@judgmentlabs.ai](mailto:support@judgmentlabs.ai)
* **DPA Requests**: For Data Processing Agreement execution, contact [legal@judgmentlabs.ai](mailto:legal@judgmentlabs.ai)
## Our Commitment
Our security and compliance certifications demonstrate our commitment to:
* **Data Protection**: Industry-leading encryption and access controls
* **System Availability**: 99.9% uptime commitment with redundant infrastructure
* **Process Integrity**: Audited security controls and continuous monitoring
* **Privacy by Design**: Built-in privacy protections and data minimization
* **Regulatory Compliance**: Adherence to GDPR, HIPAA, and industry standards
# Get Started
URL: /documentation
***
title: Get Started
icon: FastForward
-----------------
import { KeyRound, FastForward } from 'lucide-react'
[`judgeval`](https://github.com/judgmentlabs/judgeval) is an Agent Behavior Monitoring (ABM) library that helps track and judge any agent behavior in online and offline environments.
`judgeval` also enables error analysis on agent trajectories and groups trajectories by behavior and topic for deeper analysis.
judgeval is built and maintained by [Judgment Labs](https://judgmentlabs.ai). You can follow our latest updates via [GitHub](https://github.com/judgmentlabs/judgeval).
## Get Running in Under 2 Minutes
### Install Judgeval
```bash
uv add judgeval
```
```bash
pip install judgeval
```
### Get your API keys
Head to the [Judgment Platform](https://app.judgmentlabs.ai/register) and create an account. Then, copy your API key and Organization ID and set them as environment variables.
Get your free API keys} href="https://app.judgmentlabs.ai/register" icon={} external>
You get 50,000 free trace spans and 1,000 free evals each month. No credit card required.
```bash
export JUDGMENT_API_KEY="your_key_here"
export JUDGMENT_ORG_ID="your_org_id_here"
```
```bash
# Add to your .env file
JUDGMENT_API_KEY="your_key_here"
JUDGMENT_ORG_ID="your_org_id_here"
```
### Monitor your Agents' Behavior in Production
Online behavioral monitoring lets you run scorers directly on your agents in production. The instant an agent misbehaves, engineers can be alerted to push a hotfix before customers are affected.
Our server-hosted scorers run in secure Firecracker microVMs with zero impact on your application latency.
**Create a Behavior Scorer**
First, create a hosted behavior scorer that runs securely in the cloud:
```py title="helpfulness_scorer.py"
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
# Define custom example class with any fields you want to expose to the scorer
class QuestionAnswer(Example):
question: str
answer: str
# Define a server-hosted custom scorer
class HelpfulnessScorer(ExampleScorer):
name: str = "Helpfulness Scorer"
server_hosted: bool = True # Enable server hosting
async def a_score_example(self, example: QuestionAnswer):
# Custom scoring logic for agent behavior
# Can be an arbitrary combination of code and LLM calls
if len(example.answer) > 10 and "?" not in example.answer:
self.reason = "Answer is detailed and provides helpful information"
return 1.0
else:
self.reason = "Answer is too brief or unclear"
return 0.0
```
**Upload your Scorer**
Deploy your scorer to our secure infrastructure:
```bash
echo "pydantic" > requirements.txt
uv run judgeval upload_scorer helpfulness_scorer.py requirements.txt
```
```bash
echo "pydantic" > requirements.txt
judgeval upload_scorer helpfulness_scorer.py requirements.txt
```
```bash title="Terminal Output"
2025-09-27 17:54:06 - judgeval - INFO - Auto-detected scorer name: 'Helpfulness Scorer'
2025-09-27 17:54:08 - judgeval - INFO - Successfully uploaded custom scorer: Helpfulness Scorer
```
**Monitor Your Agent Using Custom Scorers**
Now instrument your agent with tracing and online evaluation:
**Note:** This example uses OpenAI. Make sure you have `OPENAI_API_KEY` set in your environment variables before running.
```py title="monitor.py"
from openai import OpenAI
from judgeval.tracer import Tracer, wrap
from helpfulness_scorer import HelpfulnessScorer, QuestionAnswer
# [!code ++:2]
judgment = Tracer(project_name="default_project") # organizes traces
client = wrap(OpenAI()) # tracks all LLM calls
@judgment.observe(span_type="tool") # [!code ++]
def format_task(question: str) -> str:
return f"Please answer the following question: {question}"
@judgment.observe(span_type="tool") # [!code ++]
def answer_question(prompt: str) -> str:
response = client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
@judgment.observe(span_type="function") # [!code ++]
def run_agent(question: str) -> str:
task = format_task(question)
answer = answer_question(task)
# [!code ++:6]
# Add online evaluation with server-hosted scorer
judgment.async_evaluate(
scorer=HelpfulnessScorer(),
example=QuestionAnswer(question=question, answer=answer),
sampling_rate=0.9 # Evaluate 90% of agent runs
)
return answer
if __name__ == "__main__":
result = run_agent("What is the capital of the United States?")
print(result)
```
Congratulations! You've just created your first trace with production monitoring. It should look like this:
**Key Benefits:**
* **`@judgment.observe()`** captures all agent interactions
* **`judgment.async_evaluate()`** runs hosted scorers with zero latency impact
* **`sampling_rate`** controls behavior scoring frequency (0.9 = 90% of agent runs)
You can instrument [Agent Behavioral Monitoring (ABM)](/documentation/performance/online-evals) on agents to [alert](/documentation/performance/alerts) when agents are misbehaving in production.
View the [alerts docs](/documentation/performance/alerts) for more information.
### Regression test your Agents
Judgeval enables you to use agent-specific behavior rubrics as regression tests in your CI pipelines to stress-test agent behavior before your agent deploys into production.
You can run evals on predefined test examples with any of your own [custom scorers](/documentation/evaluation/scorers/custom-scorers).
Evals produce a score for each example. You can run multiple scorers on the same example to score different aspects of quality.
```py title="eval.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
class CorrectnessExample(Example):
question: str
answer: str
class CorrectnessScorer(ExampleScorer):
name: str = "Correctness Scorer"
async def a_score_example(self, example: CorrectnessExample) -> float:
# Replace this logic with your own scoring logic
if "Washington, D.C." in example.answer:
self.reason = "The answer is correct because it contains 'Washington, D.C.'."
return 1.0
self.reason = "The answer is incorrect because it contains 'Washington, D.C.'."
return 0.0
example = CorrectnessExample(
question="What is the capital of the United States?", # Question to your agent (input to your agent!)
answer="The capital of the U.S. is Washington, D.C.", # Output from your agent (invoke your agent here!)
)
client.run_evaluation(
examples=[example],
scorers=[CorrectnessScorer()],
project_name="default_project",
)
```
Your test should have passed! Let's break down what happened.
* `question` and `answer{:py}` represent the question from the user and answer from the agent.
* `CorrectnessScorer(){:py}` is a custom-defined scorer that statically checks if the output contains the correct answer. This scorer can be arbitrarily defined in code, including LLM-as-a-judge and any dependencies you'd like! See examples [here](/documentation/evaluation/scorers/custom-scorers#implementation-example).
## Next Steps
Congratulations! You've just finished getting started with `judgeval` and the Judgment Platform.
Explore our features in more detail below:
Agentic Behavior Rubrics
Measure and optimize your agent along any behaviorial rubric, using techniques such as LLM-as-a-judge and human-aligned rubrics.
Agent Behavioral Monitoring (ABM)
Take action when your agents misbehave in production: alert your team, add failure cases to datasets for later optimization, and more.
# Getting Started with Self-Hosting
URL: /documentation/self-hosting
***
## title: Getting Started with Self-Hosting
Self-hosting Judgment Labs' platform is a great way to have full control over your LLM evaluation infrastructure. Instead of using our hosted platform, you can deploy your own instance of Judgment Labs' platform.
## Part 1: Infrastructure Skeleton Setup
Please have the following infrastructure set up:
1. A new/empty [AWS account](http://console.aws.amazon.com/) that you have admin access to: this will be used to host the self-hosted Judgment instance. Please write down the account ID.
2. A [Supabase](https://supabase.com/) organization that you have admin access to: this will be used to store and retrieve data for the self-hosted Judgment instance.
3. An available email address and the corresponding *app password* (see Tip below) for the email address (e.g. [no-reply@organization.com](mailto:no-reply@organization.com)). This email address will be used to send email invitations to users on the self-hosted instance.
Your app password is not your normal email password; learn about app passwords for [Gmail](https://support.google.com/mail/answer/185833?hl=en), [Outlook](https://support.microsoft.com/en-us/account-billing/how-to-get-and-use-app-passwords-5896ed9b-4263-e681-128a-a6f2979a7944), [Yahoo](https://help.yahoo.com/kb/SLN15241.html), [Zoho](https://help.zoho.com/portal/en/kb/bigin/channels/email/articles/generate-an-app-specific-password#What_is_TFA_Two_factor_Authentication), or [Fastmail](https://www.fastmail.help/hc/en-us/articles/360058752854-App-passwords)
Make sure to keep your AWS account ID and Supabase organization details secure and easily accessible, as you'll need them for the setup process.
## Part 2: Request Self-Hosting Access from Judgment Labs
Please contact us at [support@judgmentlabs.ai](mailto:support@judgmentlabs.ai) with the following information:
* The name of your organization
* An image of your organization's logo
* \[Optional] A subtitle for your organization
* Domain name for your self-hosted instance (e.g. api.organization.com) (can be any domain/subdomain name you own; this domain will be linked to your self-hosted instance as part of the setup process)
* The AWS account ID from Part 1
* Purpose of self-hosting
The domain name you provide must be one that you own and have control over, as you'll need to add DNS records during the setup process.
We will review your email request ASAP. Once approved, we will do the following:
1. Whitelist your AWS account ID to allow access to our Judgment ECR images.
2. Email you back with a backend Osiris API key that will be input as part of the setup process using the Judgment CLI (Part 3).
## Part 3: Install Judgment CLI
Make sure you have Python installed on your system before proceeding with the installation.
To install the Judgment CLI, follow these steps:
### Clone the repository
```bash
git clone https://github.com/JudgmentLabs/judgment-cli.git
```
### Navigate to the project directory
```bash
cd judgment-cli
```
### Set up a fresh Python virtual environment
Choose one of the following methods to set up your virtual environment:
```bash
python -m venv venv
source venv/bin/activate # On Windows, use: venv\Scripts\activate
```
```bash
pipenv shell
```
```bash
uv venv
source .venv/bin/activate # On Windows, use: .venv\Scripts\activate
```
### Install the package
```bash
pip install -e .
```
```bash
pipenv install -e .
```
```bash
uv pip install -e .
```
### Verifying the Installation
To verify that the CLI was installed correctly, run:
```bash
judgment --help
```
You should see a list of available commands and their descriptions.
### Available Commands
The Judgment CLI provides the following commands:
#### Self-Hosting Commands
| Command | Description |
| ----------------------------------- | ------------------------------------------------------------------------------------ |
| `judgment self-host main` | Deploy a self-hosted instance of Judgment (and optionally set up the HTTPS listener) |
| `judgment self-host https-listener` | Set up the HTTPS listener for a self-hosted Judgment instance |
## Part 4: Set Up Prerequisites
### AWS CLI Setup
You'll need to install and configure AWS CLI with the AWS account from Part 1.
```bash
brew install awscli
```
```text
Download and run the installer from https://awscli.amazonaws.com/AWSCLIV2.msi
```
```bash
sudo apt install awscli
```
After installation, configure your local environment with the relevant AWS credentials:
```bash
aws configure
```
### Terraform CLI Setup
Terraform CLI is required for deploying the AWS infrastructure.
```bash
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
```
```bash
choco install terraform
```
```text
Follow instructions https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli
```
## Part 5: Deploy Your Self-Hosted Environment
During the setup process, `.tfstate` files will be generated by Terraform.
These files keep track of the state of the infrastructure deployed by Terraform.
**DO NOT DELETE THESE FILES.**
**Create a credentials file (e.g., `creds.json`) with the following format:**
```json title="creds.json"
{
"supabase_token": "your_supabase_personal_access_token_here",
"org_id": "your_supabase_organization_id_here",
"db_password": "your_desired_supabase_database_password_here",
"invitation_sender_email": "email_address_to_send_org_invitations_from",
"invitation_sender_app_password": "app_password_for_invitation_sender_email",
"osiris_api_key": "your_osiris_api_key_here (optional)",
"openai_api_key": "your_openai_api_key_here (optional)",
"togetherai_api_key": "your_togetherai_api_key_here (optional)",
"anthropic_api_key": "your_anthropic_api_key_here (optional)"
}
```
**For `supabase_token`:** To retrieve your Supabase personal access token, you can either use an existing one or generate a new one [here](https://supabase.com/dashboard/account/tokens).
**For `org_id`:** You can retrieve it from the URL of your Supabase dashboard (make sure you have the correct organization selected in the top left corner, such as `Test Org` in the image below).
For example, if your organization URL is `https://supabase.com/dashboard/org/uwqswwrmmkxgrkfjkdex`, then your `org_id` is `uwqswwrmmkxgrkfjkdex`.
**For `db_password`:** This can be any password of your choice. It is necessary for creating the Supabase project and can be used later to directly [connect to the project database](https://supabase.com/docs/guides/database/connecting-to-postgres).
**For `invitation_sender_email` and `invitation_sender_app_password`:** These are required because the only way to add users to the self-hosted Judgment instance is via email invitations.
**For LLM API keys:** The four LLM API keys are optional. If you are not planning to run evaluations with the models that require any of these API keys, you do not need to specify them.
**Run the main self-host command. The command syntax is:**
```bash
judgment self-host main [OPTIONS]
```
**Required options:**
* `--root-judgment-email` or `-e`: Email address for the root Judgment user
* `--root-judgment-password` or `-p`: Password for the root Judgment user
* `--domain-name` or `-d`: Domain name to request SSL certificate for (make sure you own this domain)
**Optional options:**
For `--supabase-compute-size`, only "nano" is available on the free tier of Supabase. If you want to use a larger size, you will need to upgrade your organization to a paid plan.
* `--creds-file` or `-c`: Path to credentials file (default: creds.json)
* `--supabase-compute-size` or `-s`: Size of the Supabase compute instance (default: small)
* Available sizes: nano, micro, small, medium, large, xlarge, 2xlarge, 4xlarge, 8xlarge, 12xlarge, 16xlarge
* `--invitation-email-service` or `-i`: Email service for sending organization invitations (default: gmail)
* Available services: gmail, outlook, yahoo, zoho, fastmail
**Example usage:**
```bash
judgment self-host main \
--root-judgment-email root@example.com \
--root-judgment-password password \
--domain-name api.example.com \
--creds-file creds.json \
--supabase-compute-size nano \
--invitation-email-service gmail
```
**This command will:**
1. Create a new Supabase project
2. Create a root Judgment user in the self-hosted environment with the email and password provided
3. Deploy the Judgment AWS infrastructure using Terraform
4. Configure the AWS infrastructure to communicate with the new Supabase database
5. \* Request an SSL certificate from AWS Certificate Manager for the domain name provided
6. \*\* Optionally wait for the certificate to be issued and set up the HTTPS listener
\*For the certificate to be issued, this command will return two DNS records that must be manually added to your DNS registrar/service.
\*\*You will be prompted to either continue with the HTTPS listener setup now or to come back later. If you choose to proceed with the setup now, the program will wait for the certificate to be issued before continuing.
### Setting up the HTTPS listener
This step is optional; you can choose to have the HTTPS listener setup done as part of the main self-host command.
This command will only work after `judgment self-host main` has already been run AND the ACM certificate has been issued. To accomplish this:
1. Add the two DNS records returned by the main self-host command to your DNS registrar/service
2. Monitor the ACM console [here](https://console.aws.amazon.com/acm/home) until the certificate has status 'Issued'
To set up the HTTPS listener, run:
```bash
judgment self-host https-listener
```
This command will:
1. Set up the HTTPS listener with the certificate issued by AWS Certificate Manager
2. Return the url to the HTTPS-enabled domain which now points to your self-hosted Judgment server
## Part 6: Accessing Your Self-Hosted Environment
Your self-hosted Judgment API URL (referenced as `self_hosted_judgment_api_url` in this section) should be in the format `https://{self_hosted_judgment_domain}` (e.g. `https://api.organization.com`).
### From the Judgeval SDK
You can access your self-hosted instance by setting the following environment variables:
```
JUDGMENT_API_URL = "self_hosted_judgment_api_url"
JUDGMENT_API_KEY = "your_api_key"
JUDGMENT_ORG_ID = "your_org_id"
```
Afterwards, Judgeval can be used as you normally would.
### From the Judgment platform website
Visit the url `https://app.judgmentlabs.ai/login?api_url={self_hosted_judgment_api_url}` to login to your self-hosted instance. Your self-hosted Judgment API URL will be whitelisted when we review your request from Part 2.
You should be able to log in with the root user you configured during the setup process (`--root-judgment-email` and `--root-judgment-password` from the `self-host main` command).
#### Adding more users to the self-hosted instance
For security reasons, users cannot register themselves on the self-hosted instance. Instead, you can add new users via email invitations to organizations.
To add a new user, make sure you're currently in the workspace/organization you want to add the new user to. Then, visit the [workspace member settings](https://app.judgmentlabs.ai/app/settings/members) and click the "Invite User" button. This process will send an email invitation to the new user to join the organization.
# Interactive Demo
URL: /interactive-demo
Try out our AI-powered research agent with Judgeval tracing
***
title: Interactive Demo
description: Try out our AI-powered research agent with Judgeval tracing
full: true
----------
### Create an account
To view the detailed traces from your conversations, create a [Judgment Labs](https://app.judgmentlabs.ai/register) account.
### Start a conversation
This demo shows you both sides of AI agent interactions: the conversation **and** the detailed traces showing how judgeval traces your agent runs.
Chat with our AI research agent below. Ask it to research any topic, analyze data, or answer complex questions.
# Dataset
URL: /sdk-reference/dataset
Dataset class for managing datasets of Examples and Traces in Judgeval
***
title: Dataset
description: Dataset class for managing datasets of Examples and Traces in Judgeval
-----------------------------------------------------------------------------------
## Overview
The `Dataset` class provides both methods for dataset operations and serves as the return type for dataset instances. When you call `Dataset.create()` or `Dataset.get()`, you receive a `Dataset` instance with additional methods for managing the dataset's contents.
## Quick Start Example
```python
from judgeval.dataset import Dataset
from judgeval.data import Example
dataset = Dataset.create(
name="qa_dataset",
project_name="default_project",
examples=[Example(input="What is the powerhouse of the cell?", actual_output="The mitochondria.")]
)
dataset = Dataset.get(
name="qa_dataset",
project_name="default_project",
)
examples = []
example = Example(input="Sample question?", output="Sample answer.")
examples.append(example)
dataset.add_examples(examples=examples)
```
## Dataset Creation & Retrieval
### `Dataset.create(){:py}`
Create a new evaluation dataset for storage and reuse across multiple evaluation runs. Note this command pushes the dataset to the Judgment platform.
#### `name` \[!toc]
Name of the dataset
```py
"qa_dataset"
```
#### `project_name` \[!toc]
Name of the project
```py
"question_answering"
```
#### `examples` \[!toc]
List of examples to include in the dataset. See [Example](/sdk-reference/data-types/core-types#example) for details on the structure.
```py
[Example(input="...", actual_output="...")]
```
#### `traces` \[!toc]
List of traces to include in the dataset. See [Trace](/sdk-reference/data-types/core-types#trace) for details on the structure.
```py
[Trace(...)]
```
#### `overwrite` \[!toc]
Whether to overwrite an existing dataset with the same name.
#### Returns \[!toc]
A `Dataset` instance for further operations
### `JudgmentAPIError` \[!toc]
Raised when a dataset with the same name already exists in the project and `overwrite=False`. See [JudgmentAPIError](/sdk-reference/data-types/response-types#judgmentapierror) for details.
```py title="dataset.py"
from judgeval.dataset import Dataset
from judgeval.data import Example
dataset = Dataset.create(
name="qa_dataset",
project_name="default_project",
examples=[Example(input="What is the powerhouse of the cell?", actual_output="The mitochondria.")]
)
```
### `Dataset.get(){:py}`
Retrieve a dataset from the Judgment platform by its name and project name.
#### `name` \[!toc]
The name of the dataset to retrieve.
```py
"my_dataset"
```
#### `project_name` \[!toc]
The name of the project where the dataset is stored.
```py
"default_project"
```
#### Returns \[!toc]
A `Dataset` instance for further operations
```py title="retrieve_dataset.py"
from judgeval.dataset import Dataset
dataset = Dataset.get(
name="qa_dataset",
project_name="default_project",
)
print(dataset.examples)
```
## Dataset Management
Once you have a `Dataset` instance (from `Dataset.create()` or `Dataset.get()`), you can use these methods to manage its contents:
> **Note:** All instance methods automatically update the dataset and push changes to the Judgment platform.
### `dataset.add_examples(){:py}`
Add examples to the dataset.
#### `examples` \[!toc]
List of examples to add to the dataset.
#### Returns \[!toc]
`True` if examples were added successfully
```py title="add_examples.py"
from judgeval.dataset import Dataset
from judgeval.data import Example
dataset = Dataset.get(
name="qa_dataset",
project_name="default_project",
)
example = Example(input="Sample question?", output="Sample answer.")
examples = [example]
dataset.add_examples(examples=examples)
```
## Dataset Properties
When you have a `Dataset` instance, it provides access to the following properties:
### `Dataset{:py}`
### `dataset.name` \[!toc]
**Type:** `str` (read-only)
The name of the dataset.
### `dataset.project_name` \[!toc]
**Type:** `str` (read-only)
The project name where the dataset is stored.
### `dataset.examples` \[!toc]
**Type:** `List[Example]` (read-only)
List of [examples](/sdk-reference/data-types/core-types#example) contained in the dataset.
### `dataset.traces` \[!toc]
**Type:** `List[Trace]` (read-only)
List of [traces](/sdk-reference/data-types/core-types#trace) contained in the dataset (if any).
### `dataset.id` \[!toc]
**Type:** `str` (read-only)
Unique identifier for the dataset on the Judgment platform.
# JudgmentClient
URL: /sdk-reference/judgment-client
Run evaluations with the JudgmentClient class to test for regressions and run A/B tests on your agents.
***
title: JudgmentClient
description: Run evaluations with the JudgmentClient class to test for regressions and run A/B tests on your agents.
--------------------------------------------------------------------------------------------------------------------
## Overview
The JudgmentClient is your primary interface for interacting with the Judgment platform. It provides methods for running evaluations, managing datasets, handling traces, and more.
## Authentication
Set up your credentials using environment variables:
```bash
export JUDGMENT_API_KEY="your_key_here"
export JUDGMENT_ORG_ID="your_org_id_here"
```
```bash
# Add to your .env file
JUDGMENT_API_KEY="your_key_here"
JUDGMENT_ORG_ID="your_org_id_here"
```
### `JudgmentClient(){:py}`
Initialize a `JudgmentClient{:py}` object.
### `api_key` \[!toc]
Your Judgment API key. **Recommended:** Set using the `JUDGMENT_API_KEY` environment variable instead of passing directly.
### `organization_id` \[!toc]
Your organization ID. **Recommended:** Set using the `JUDGMENT_ORG_ID` environment variable instead of passing directly.
```py title="judgment_client.py"
from judgeval import JudgmentClient
import os
from dotenv import load_dotenv
load_dotenv() # Load environment variables from .env file
# Automatically uses JUDGMENT_API_KEY and JUDGMENT_ORG_ID from environment
client = JudgmentClient()
# Manually pass in API key and Organization ID
client = JudgmentClient(
api_key=os.getenv('JUDGMENT_API_KEY'),
organization_id=os.getenv("JUDGMENT_ORG_ID")
)
```
***
### `client.run_evaluation(){:py}`
Execute an evaluation of examples using one or more scorers to measure performance and quality of your AI models.
### `examples` \[!toc]
List of [Example](/sdk-reference/data-types/core-types#example) objects (or any class inheriting from Example) containing inputs, outputs, and metadata to evaluate against your agents
```py
[Example(...)]
```
### `scorers` \[!toc]
List of scorers to use for evaluation, such as `PromptScorer`, `CustomScorer`, or any custom defined [ExampleScorer](/sdk-reference/data-types/core-types#examplescorer)
```py
[ExampleScorer(...)]
```
### `model` \[!toc]
Model used as judge when using LLM as a Judge
```py
"gpt-5"
```
### `project_name` \[!toc]
Name of the project for organization
```py
"my_qa_project"
```
### `eval_run_name` \[!toc]
Name for the evaluation run
```py
"experiment_v1"
```
### `assert_test` \[!toc]
Runs evaluations as unit tests, raising an exception if the score falls below the defined threshold.
```py
"True"
```
```py title="resolution.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
example = CustomerRequest(request="Where is my package?", response="Your package will arrive tomorrow at 10:00 AM.")
res = client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
)
# Example with a failing test using assert_test=True
# This will raise an error because the response does not contain the word "package"
try:
example = CustomerRequest(request="Where is my package?", response="Empty response.")
client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
assert_test=True, # This will raise an error if any test fails
)
except Exception as e:
print(f"Test assertion failed: {e}")
```
A list of `ScoringResult{:py}` objects. See [Return Types](#return-types) for detailed structure.
```py
[
ScoringResult(
success=False,
scorers_data=[ScorerData(...)],
name=None,
data_object=Example(...),
trace_id=None,
run_duration=None,
evaluation_cost=None
)
]
```
## Return Types
### `ScoringResult`
The `ScoringResult{:py}` object contains the evaluation output of one or more scorers applied to a single example.
| Attribute |
Type |
Description |
| success |
bool |
Whether all scorers applied to this example succeeded |
| scorers\_data |
List\[ScorerData] |
Individual scorer results and metadata |
| data\_object |
Example |
The original example object that was evaluated |
| run\_duration |
Optional\[float] |
Time taken to complete the evaluation |
| trace\_id |
Optional\[str] |
Associated trace ID for trace-based evaluations |
| evaluation\_cost |
Optional\[float] |
Cost of the evaluation in USD |
### `ScorerData`
Each `ScorerData{:py}` object within `scorers_data{:py}` contains the results from an individual scorer:
| Attribute |
Type |
Description |
| name |
str |
Name of the scorer |
| threshold |
float |
Threshold used for pass/fail determination |
| success |
bool |
Whether this scorer passed its threshold |
| score |
Optional\[float] |
Numerical score from the scorer |
| reason |
Optional\[str] |
Explanation for the score/decision |
| evaluation\_model |
Optional\[Union\[List\[str], str]] |
Model(s) used for evaluation |
| error |
Optional\[str] |
Error message if scoring failed |
```py title="accessing_results.py"
# Example of accessing ScoringResult data
results = client.run_evaluation(examples, scorers)
for result in results:
print(f"Overall success: {result.success}")
print(f"Example input: {result.data_object.input}")
for scorer_data in result.scorers_data:
print(f"Scorer '{scorer_data.name}': {scorer_data.score} (threshold: {scorer_data.threshold})")
if scorer_data.reason:
print(f"Reason: {scorer_data.reason}")
```
## Error Handling
The JudgmentClient raises specific exceptions for different error conditions:
### `JudgmentAPIError`
Raised when API requests fail or server errors occur
### `ValueError`
Raised when invalid parameters or configuration are provided
### `FileNotFoundError`
Raised when test files or datasets are missing
```py title="error_handling.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
from judgeval.exceptions import JudgmentAPIError
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
example = CustomerRequest(request="Where is my package?", response="Your package will arrive tomorrow at 10:00 AM.")
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
try:
res = client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
)
except JudgmentAPIError as e:
print(f"API Error: {e}")
except ValueError as e:
print(f"Invalid parameters: {e}")
except FileNotFoundError as e:
print(f"File not found: {e}")
```
# PromptScorer
URL: /sdk-reference/prompt-scorer
Evaluate agent behavior based on a rubric you define and iterate on the platform.
***
title: PromptScorer
description: Evaluate agent behavior based on a rubric you define and iterate on the platform.
----------------------------------------------------------------------------------------------
## Overview
A `PromptScorer` is a powerful tool for evaluating your LLM system using use-case specific, natural language rubrics.
PromptScorer's make it easy to prototype your evaluation rubrics—you can easily set up a new criteria and test them on a few examples in the scorer playground, then evaluate your agents' behavior in production with real customer usage.
All PromptScorer methods automatically sync changes with the Judgment platform.
## Quick Start Example
```py title="create_and_use_prompt_scorer.py"
from openai import OpenAI
from judgeval.scorers import PromptScorer
from judgeval.tracer import Tracer, wrap
from judgeval.data import Example
# Initialize tracer
judgment = Tracer(
project_name="default_project"
)
# Auto-trace LLM calls
client = wrap(OpenAI())
# Initialize PromptScorer
scorer = PromptScorer.create(
name="PositivityScorer",
prompt="Is the response positive or negative? Question: {{input}}, response: {{actual_output}}",
options={"positive" : 1, "negative" : 0}
)
class QAAgent:
def __init__(self, client):
self.client = client
@judgment.observe(span_type="tool")
def process_query(self, query):
response = self.client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assitant"},
{"role": "user", "content": f"I have a query: {query}"}]
) # Automatically traced
return f"Response: {response.choices[0].message.content}"
# Basic function tracing
@judgment.agent()
@judgment.observe(span_type="agent")
def invoke_agent(self, query):
result = self.process_query(query)
judgment.async_evaluate(
scorer=scorer,
example=Example(input=query, actual_output=result),
model="gpt-5"
)
return result
if __name__ == "__main__":
agent = QAAgent(client)
print(agent.invoke_agent("What is the capital of the United States?"))
```
## Authentication
Set up your credentials using environment variables:
```bash
export JUDGMENT_API_KEY="your_key_here"
export JUDGMENT_ORG_ID="your_org_id_here"
```
```bash
# Add to your .env file
JUDGMENT_API_KEY="your_key_here"
JUDGMENT_ORG_ID="your_org_id_here"
```
## **PromptScorer Creation & Retrieval**
## `PromptScorer.create()`/`TracePromptScorer.create(){:py}`
Initialize a `PromptScorer{:py}` or `TracePromptScorer{:py}` object.
### `name` \[!toc]
The name of the PromptScorer
### `prompt`\[!toc]
The prompt used by the LLM judge to make an evaluation
### `options`\[!toc]
If specified, the LLM judge will pick from one of the choices, and the score will be the one corresponding to the choice
### `judgment_api_key`\[!toc]
Recommended - set using the `JUDGMENT_API_KEY` environment variable
### `organization_id`\[!toc]
Recommended - set using the `JUDGMENT_ORG_ID` environment variable
#### Returns\[!toc]
A `PromptScorer` instance
```py title="create_prompt_scorer.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.create(
name="Test Scorer",
prompt="Is the response positive or negative? Response: {{actual_output}}",
options={"positive" : 1, "negative" : 0}
)
```
## `PromptScorer.get()`/`TracePromptScorer.get(){:py}`
Retrieve a `PromptScorer{:py}` or `TracePromptScorer{:py}` object that had already been created for the organization.
### `name`\[!toc]
The name of the PromptScorer you would like to retrieve
### `judgment_api_key`\[!toc]
Recommended - set using the `JUDGMENT_API_KEY` environment variable
### `organization_id`\[!toc]
Recommended - set using the `JUDGMENT_ORG_ID` environment variable
#### Returns\[!toc]
A `PromptScorer` instance
```py title="get_prompt_scorer.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
```
## **PromptScorer Management**
### `scorer.append_to_prompt(){:py}`
Add to the prompt for your PromptScorer
### `prompt_addition`\[!toc]
This string will be added to the existing prompt for the scorer.
#### Returns\[!toc]
None
```py title="append_to_prompt.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
scorer.append_to_prompt("Consider the overall tone, word choice, and emotional sentiment when making your determination.")
```
### `scorer.set_threshold(){:py}`
Update the threshold for your PromptScorer
### `threshold`\[!toc]
The new threshold you would like the PromptScorer to use
#### Returns\[!toc]
None
```py title="set_threshold.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
scorer.set_threshold(0.5)
```
### `scorer.set_prompt(){:py}`
Update the prompt for your PromptScorer
### `prompt`\[!toc]
The new prompt you would like the PromptScorer to use
#### Returns\[!toc]
None
```py title="set_prompt.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
scorer.set_prompt("Is the response helpful to the question? Question: {{input}}, response: {{actual_output}}")
```
### `scorer.set_options(){:py}`
Update the options for your PromptScorer
### `options`\[!toc]
The new options you would like the PromptScorer to use
#### Returns\[!toc]
None
```py title="set_options.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
scorer.set_options({"Yes" : 1, "No" : 0})
```
### `scorer.get_threshold(){:py}`
Retrieve the threshold for your PromptScorer
None
#### Returns\[!toc]
The threshold value for the PromptScorer
```py title="get_threshold.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
threshold = scorer.get_threshold()
```
### `scorer.get_prompt(){:py}`
Retrieve the prompt for your PromptScorer
None
#### Returns\[!toc]
The prompt string for the PromptScorer
```py title="get_prompt.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
prompt = scorer.get_prompt()
```
### `scorer.get_options(){:py}`
Retrieve the options for your PromptScorer
None
#### Returns\[!toc]
The options dictionary for the PromptScorer
```py title="get_options.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
options = scorer.get_options()
```
### `scorer.get_name(){:py}`
Retrieve the name for your PromptScorer
None
#### Returns\[!toc]
The name of the PromptScorer
```py title="get_name.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
name = scorer.get_name()
```
### `scorer.get_config(){:py}`
Retrieve the name, prompt, options, and threshold for your PromptScorer in a dictionary format
None
#### Returns\[!toc]
Dictionary containing the name, prompt, options, and threshold for the PromptScorer
```py title="get_config.py"
from judgeval.scorers import PromptScorer
scorer = PromptScorer.get(
name="Test Scorer"
)
config = scorer.get_config()
```
# Tracer
URL: /sdk-reference/tracing
Track agent behavior and evaluate performance in real-time with the Tracer class.
***
title: Tracer
description: Track agent behavior and evaluate performance in real-time with the Tracer class.
----------------------------------------------------------------------------------------------
## Overview
The `Tracer` class provides comprehensive observability for AI agents and LLM applications. It automatically captures execution traces, spans, and performance metrics while enabling real-time evaluation and monitoring through the Judgment platform.
The `Tracer` is implemented as a **singleton** - only one instance exists per application. Multiple `Tracer()` initializations will return the same instance. All tracing is built on **OpenTelemetry** standards, ensuring compatibility with the broader observability ecosystem.
## Quick Start Example
```python
from judgeval.tracer import Tracer, wrap
from openai import OpenAI
# Initialize tracer
judgment = Tracer(
project_name="default_project"
)
# Auto-trace LLM calls
client = wrap(OpenAI())
class QAAgent:
def __init__(self, client):
self.client = client
@judgment.observe(span_type="tool")
def process_query(self, query):
response = self.client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assitant"},
{"role": "user", "content": f"I have a query: {query}"}]
) # Automatically traced
return f"Response: {response.choices[0].message.content}"
# Basic function tracing
@judgment.agent()
@judgment.observe(span_type="agent")
def invoke_agent(self, query):
result = self.process_query(query)
return result
if __name__ == "__main__":
agent = QAAgent(client)
print(agent.invoke_agent("What is the capital of the United States?"))
```
## How Tracing Works
The Tracer automatically captures comprehensive execution data from your AI agents:
**Key Components:**
* **`@judgment.observe()`** captures all tool interactions, inputs, outputs, and execution time
* **`wrap(OpenAI())`** automatically tracks all LLM API calls including token usage and costs
* **`@judgment.agent()`** identifies which agent is responsible for each tool call in multi-agent systems
**What Gets Captured:**
* Tool usage and results
* LLM API calls (model, messages, tokens, costs)
* Function inputs and outputs
* Execution duration and hierarchy
* Error states and debugging information
**Automatic Monitoring:**
* All traced data flows to the Judgment platform in real-time
* Zero-latency impact on your application performance
* Comprehensive observability across your entire agent workflow
## Tracer Initialization
The Tracer is your primary interface for adding observability to your AI agents. It provides methods for tracing function execution, evaluating performance, and collecting comprehensive environment interaction data.
### `Tracer(){:py}`
Initialize a `Tracer{:py}` object.
#### `api_key` \[!toc]
Recommended - set using the `JUDGMENT_API_KEY` environment variable
#### `organization_id` \[!toc]
Recommended - set using the `JUDGMENT_ORG_ID` environment variable
#### `project_name` \[!toc]
Project name override
#### `enable_monitoring` \[!toc]
If you need to toggle monitoring on and off
#### `enable_evaluations` \[!toc]
If you need to toggle evaluations on and off for `async_evaluate(){:py}`
#### `resource_attributes` \[!toc]
OpenTelemetry resource attributes to attach to all spans. Resource attributes describe the entity producing the telemetry data (e.g., service name, version, environment). See the [OpenTelemetry Resource specification](https://opentelemetry.io/docs/specs/otel/configuration/sdk-environment-variables/) for standard attributes.
```py title="tracer.py"
from judgeval.tracer import Tracer
judgment = Tracer(
project_name="default_project"
)
@judgment.observe(span_type="function")
def answer_question(question: str) -> str:
answer = "The capital of the United States is Washington, D.C."
return answer
@judgment.observe(span_type="tool")
def process_request(question: str) -> str:
answer = answer_question(question)
return answer
if __name__ == "__main__":
print(process_request("What is the capital of the United States?"))
```
```py title="tracer_otel.py"
from judgeval.tracer import Tracer
from opentelemetry.sdk.trace import TracerProvider
tracer_provider = TracerProvider()
# Initialize tracer with OpenTelemetry configuration
judgment = Tracer(
project_name="default_project",
resource_attributes={
"service.name": "my-ai-agent",
"service.version": "1.2.0",
"deployment.environment": "production"
}
)
tracer_provider.add_span_processor(judgment.get_processor())
tracer = tracer_provider.get_tracer(__name__)
def answer_question(question: str) -> str:
with tracer.start_as_current_span("answer_question_span") as span:
span.set_attribute("question", question)
answer = "The capital of the United States is Washington, D.C."
span.set_attribute("answer", answer)
return answer
def process_request(question: str) -> str:
with tracer.start_as_current_span("process_request_span") as span:
span.set_attribute("input", question)
answer = answer_question(question)
span.set_attribute("output", answer)
return answer
if __name__ == "__main__":
print(process_request("What is the capital of the United States?"))
```
***
## Agent Tracking and Online Evals
### `@tracer.observe(){:py}`
Records an observation or output during a trace. This is useful for capturing intermediate steps, tool results, or decisions made by the agent. Optionally, provide a scorer config to run an evaluation on the trace.
#### `func` \[!toc]
The function to decorate (automatically provided when used as decorator)
#### `name` \[!toc]
Optional custom name for the span (defaults to function name)
```py
"custom_span_name"
```
#### `span_type` \[!toc]
Type of span to create. Available options:
* `"span"`: General span (default)
* `"tool"`: For functions that should be tracked and exported as agent tools
* `"function"`: For main functions or entry points
* `"llm"`: For language model calls (automatically applied to wrapped clients)
LLM clients wrapped using `wrap(){:py}` automatically use the `"llm"` span type without needing manual decoration.
```py
"tool" # or "function", "llm", "span"
```
#### `scorer_config`
Configuration for running an evaluation on the trace or sub-trace. When `scorer_config` is provided, a trace evaluation will be run for the sub-trace/span tree with the decorated function as the root. See [`TraceScorerConfig`](#tracescorerconfigpy) for more details
```py
# retrieve/create a trace scorer to be used with the TraceScorerConfig
trace_scorer = TracePromptScorer.get(name="sample_trace_scorer")
TraceScorerConfig(
scorer=trace_scorer,
sampling_rate=0.5,
)
```
```py title="trace.py"
from openai import OpenAI
from judgeval.tracer import Tracer
client = OpenAI()
tracer = Tracer(project_name='default_project', deep_tracing=False)
@tracer.observe(span_type="tool")
def search_web(query):
return f"Results for: {query}"
@tracer.observe(span_type="retriever")
def get_database(query):
return f"Database results for: {query}"
@tracer.observe(span_type="function")
def run_agent(user_query):
# Use tools based on query
if "database" in user_query:
info = get_database(user_query)
else:
info = search_web(user_query)
prompt = f"Context: {info}, Question: {user_query}"
# Generate response
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
```
***
### `wrap(){:py}`
Wraps an API client to add tracing capabilities. Supports OpenAI, Together, Anthropic, and Google GenAI clients. Patches methods like `.create{:py}`, Anthropic's `.stream{:py}`, and OpenAI's `.responses.create{:py}` and `.beta.chat.completions.parse{:py}` methods using a wrapper class.
#### `client` \[!toc]
API client to wrap (OpenAI, Anthropic, Together, Google GenAI, Groq)
```py
OpenAI()
```
```py title="wrapped_api_client.py"
from openai import OpenAI
from judgeval.tracer import wrap
client = OpenAI()
wrapped_client = wrap(client)
# All API calls are now automatically traced
response = wrapped_client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello"}]
)
# Streaming calls are also traced
stream = wrapped_client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello"}],
stream=True
)
```
***
### `tracer.async_evaluate(){:py}`
Runs quality evaluations on the current trace/span using specified scorers. You can provide either an Example object or individual evaluation parameters (input, actual\_output, etc.).
#### `scorer` \[!toc]
A evaluation scorer to run. See [Configuration Types](/sdk-reference/data-types/config-types) for available scorer options.
```py
FaithfulnessScorer()
```
#### `example` \[!toc]
Example object containing evaluation data. See [Example](/sdk-reference/data-types/core-types#example) for structure details.
#### `model` \[!toc]
Model name for evaluation
```py
"gpt-5"
```
#### `sampling_rate` \[!toc]
A float between 0 and 1 representing the chance the eval should be sampled
```py
0.75 # Eval occurs 75% of the time
```
```py title="async_evaluate.py"
from judgeval.scorers import AnswerRelevancyScorer
from judgeval.data import Example
from judgeval.tracer import Tracer
judgment = Tracer(project_name="default_project")
@judgment.observe(span_type="function")
def agent(question: str) -> str:
answer = "Paris is the capital of France"
# Create example object
example = Example(
input=question,
actual_output=answer,
)
# Evaluate using Example
judgment.async_evaluate(
scorer=AnswerRelevancyScorer(threshold=0.5),
example=example,
model="gpt-5",
sampling_rate=0.9
)
return answer
if __name__ == "__main__":
print(agent("What is the capital of France?"))
```
***
## Multi-Agent Monitoring
### `@tracer.agent(){:py}`
Method decorator for agentic systems that assigns an identifier to each agent and enables tracking of their internal state variables. Essential for monitoring and debugging single or multi-agent systems where you need to track each agent's behavior and state separately. This decorator should be used on the entry point method of your agent class.
#### `identifier` \[!toc]
The identifier to associate with the class whose method is decorated. This will be used as the instance name in traces.
```py
"id"
```
```py title="agent.py"
from judgeval.tracer import Tracer
judgment = Tracer(project_name="default_project")
class TravelAgent:
def __init__(self, id):
self.id = id
@judgment.observe(span_type="tool")
def book_flight(self, destination):
return f"Flight booked to {destination}!"
@judgment.agent(identifier="id")
@judgment.observe(span_type="function")
def invoke_agent(self, destination):
flight_info = self.book_flight(destination)
return f"Here is your requested flight info: {flight_info}"
if __name__ == "__main__":
agent = TravelAgent("travel_agent_1")
print(agent.invoke_agent("Paris"))
agent2 = TravelAgent("travel_agent_2")
print(agent2.invoke_agent("New York"))
```
***
### Multi-Agent System Tracing
When working with multi-agent systems, use the `@judgment.agent()` decorator to track which agent is responsible for each tool call in your trace.
Only decorate the **entry point method** of each agent with `@judgment.agent()` and `@judgment.observe()`. Other methods within the same agent only need `@judgment.observe()`.
Here's a complete multi-agent system example with a flat folder structure:
```python title="main.py"
from planning_agent import PlanningAgent
if __name__ == "__main__":
planning_agent = PlanningAgent("planner-1")
goal = "Build a multi-agent system"
result = planning_agent.plan(goal)
print(result)
```
```python title="utils.py"
from judgeval.tracer import Tracer
judgment = Tracer(project_name="multi-agent-system")
```
```python title="planning_agent.py"
from utils import judgment
from research_agent import ResearchAgent
from task_agent import TaskAgent
class PlanningAgent:
def __init__(self, id):
self.id = id
@judgment.agent() # Only add @judgment.agent() to the entry point function of the agent
@judgment.observe()
def invoke_agent(self, goal):
print(f"Agent {self.id} is planning for goal: {goal}")
research_agent = ResearchAgent("Researcher1")
task_agent = TaskAgent("Tasker1")
research_results = research_agent.invoke_agent(goal)
task_result = task_agent.invoke_agent(research_results)
return f"Results from planning and executing for goal '{goal}': {task_result}"
@judgment.observe() # No need to add @judgment.agent() here
def random_tool(self):
pass
```
```python title="research_agent.py"
from utils import judgment
class ResearchAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, topic):
return f"Research notes for topic: {topic}: Findings and insights include..."
```
```python title="task_agent.py"
from utils import judgment
class TaskAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, task):
result = f"Performed task: {task}, here are the results: Results include..."
return result
```
The trace will show up in the Judgment platform clearly indicating which agent called which method:
Each agent's tool calls are clearly associated with their respective classes, making it easy to follow the execution flow across your multi-agent system.
***
### `TraceScorerConfig(){:py}`
Initialize a `TraceScorerConfig` object for running an evaluation on the trace.
#### `scorer`
The scorer to run on the trace
#### `model`
Model name for evaluation
```py
"gpt-4.1"
```
#### `sampling_rate`
A float between 0 and 1 representing the chance the eval should be sampled
```py
0.75 # Eval occurs 75% of the time
```
#### `run_condition`
A function that returns a boolean indicating whether the eval should be run. When `TraceScorerConfig` is used in `@tracer.observe()`, `run_condition` is called with the decorated function's arguments
```py
lambda x: x > 10
```
For the above example, if this `TraceScorerConfig` instance is passed into a `@tracer.observe()` that decorates a function taking `x` as an argument, then the trace eval will only run if `x > 10` when the decorated function is called
```py title="trace_scorer_config.py"
judgment = Tracer(project_name="default_project")
# Retrieve a trace scorer to be used with the TraceScorerConfig
trace_scorer = TracePromptScorer.get(name="sample_trace_scorer")
# A trace eval is only triggered if process_request() is called with x > 10
@judgment.observe(span_type="function", scorer_config=TraceScorerConfig(
scorer=trace_scorer,
sampling_rate=1.0,
run_condition=lambda x: x > 10
))
def process_request(x):
return x + 1
```
In the above example, a trace eval will be run for the trace/sub-trace with the process\_request() function as the root.
***
## Current Span Access
### `tracer.get_current_span(){:py}`
Returns the current span object for direct access to span properties and methods, useful for debugging and inspection.
### Available Span Properties
The current span object provides these properties for inspection and debugging:
| Property |
Type |
Description |
| span\_id |
str |
Unique identifier for this span |
| trace\_id |
str |
ID of the parent trace |
| function |
str |
Name of the function being traced |
| span\_type |
str |
Type of span ("span", "tool", "llm", "evaluation", "chain") |
| inputs |
dict |
Input parameters for this span |
| output |
Any |
Output/result of the span execution |
| duration |
float |
Execution time in seconds |
| depth |
int |
Nesting depth in the trace hierarchy |
| parent\_span\_id |
str | None |
ID of the parent span (if nested) |
| agent\_name |
str | None |
Name of the agent executing this span |
| has\_evaluation |
bool |
Whether this span has evaluation runs |
| evaluation\_runs |
List\[EvaluationRun] |
List of evaluations run on this span |
| usage |
TraceUsage | None |
Token usage and cost information |
| error |
Dict\[str, Any] | None |
Error information if span failed |
| state\_before |
dict | None |
Agent state before execution |
| state\_after |
dict | None |
Agent state after execution |
### Example Usage
```python
@tracer.observe(span_type="tool")
def debug_tool(query):
span = tracer.get_current_span()
if span:
# Access span properties for debugging
print(f"🔧 Executing {span.function} (ID: {span.span_id})")
print(f"📊 Depth: {span.depth}, Type: {span.span_type}")
print(f"📥 Inputs: {span.inputs}")
# Check parent relationship
if span.parent_span_id:
print(f"👆 Parent span: {span.parent_span_id}")
# Monitor execution state
if span.agent_name:
print(f"🤖 Agent: {span.agent_name}")
result = perform_search(query)
# Check span after execution
if span:
print(f"📤 Output: {span.output}")
print(f"⏱️ Duration: {span.duration}s")
if span.has_evaluation:
print(f"✅ Has {len(span.evaluation_runs)} evaluations")
if span.error:
print(f"❌ Error: {span.error}")
return result
```
## Getting Started
```python
from judgeval import Tracer
# Initialize tracer
tracer = Tracer(
api_key="your_api_key",
project_name="default_project"
)
# Basic function tracing
@tracer.observe(span_type="agent")
def my_agent(query):
tracer.update_metadata({"user_query": query})
result = process_query(query)
tracer.log("Processing completed", label="info")
return result
# Auto-trace LLM calls
from openai import OpenAI
from judgeval import wrap
client = wrap(OpenAI())
response = client.chat.completions.create(...) # Automatically traced
```
# v0.1 Release Notes (July 1, 2025)
URL: /changelog/v0.01
***
## title: "v0.1 Release Notes (July 1, 2025)"
## New Features
#### Trace Management
* **Custom Trace Tagging**: Add and remove custom tags on individual traces to better organize and categorize your trace data (e.g., environment, feature, or workflow type)
## Fixes
#### Improved Markdown Display
Fixed layout issues where markdown content wasn't properly fitting container width, improving readability.
## Improvements
No improvements in this release.
## New Features
#### Enhanced Prompt Scorer Integration
* **Automatic Database Sync**: Prompt scorers automatically push to database when created or updated through the SDK. [Learn about PromptScorers →](https://docs.judgmentlabs.ai/documentation/evaluation/scorers/prompt-scorer)
* **Smart Initialization**: Initialize ClassifierScorer objects with automatic slug generation or fetch existing scorers from database using slugs
## Fixes
No bug fixes in this release.
## Improvements
#### Performance
* **Faster Evaluations**: All evaluations now route through optimized async worker servers for improved experiment speed
* **Industry-Standard Span Export**: Migrated to batch OpenTelemetry span exporter in C++ from custom Python implementation for better reliability, scalability, and throughput
* **Enhanced Network Resilience**: Added intelligent timeout handling for network requests, preventing blocking threads and potential starvation in production environments
* **Advanced Span Lifecycle Management**: Improved span object lifecycle management for better span ingestion event handling
#### Developer Experience
* **Updated Cursor Rules**: Enhanced Cursor integration rules to assist with building agents using Judgeval. [Set up Cursor rules →](https://docs.judgmentlabs.ai/documentation/developer-tools/cursor/cursor-rules#cursor-rules-file)
#### User Experience
* **Consistent Error Pages**: Standardized error and not-found page designs across the platform for a more polished user experience
## New Features
#### Role-Based Access Control
* **Multi-Tier Permissions**: Implement viewer, developer, admin, and owner roles to control user access within organizations
* **Granular Access Control**: Viewers get read-only access to non-sensitive data, developers handle all non-administrative tasks, with finer controls coming soon
#### Customer Usage Analytics
* **Usage Monitoring Dashboard**: Track and monitor customer usage trends with visual graphs showing usage vs time and top customers by cost and token consumption
* **SDK Customer ID Assignment**: Set customer id to track customer usage by using `tracer.set_customer_id()`. [Track customer LLM usage →](https://docs.judgmentlabs.ai/documentation/tracing/metadata#metadata-options)
#### API Integrations
* **Enhanced Token Tracking**: Added support for input cache tokens across OpenAI, Gemini, and Anthropic APIs
* **Together API Support**: Extended `wrap()` functionality to include Together API clients. [Set up Together tracing →](https://docs.judgmentlabs.ai/documentation/tracing/introduction#tracing)
## Fixes
No bug fixes in this release.
## Improvements
#### Platform Reliability
* **Standardized Parameters**: Consistent naming conventions across evaluation and tracing methods
* **Improved Database Performance**: Optimized trace span ingestion for increased throughput and decreased latency
### Initial Release
* Initial platform launch!
# v0.2 Release Notes (July 23, 2025)
URL: /changelog/v0.02
***
## title: "v0.2 Release Notes (July 23, 2025)"
## New Features
#### Multi-Agent System Support
* **Multi-Agent System Tracing**: Enhanced trace view with agent tags displaying agent names when provided for better multi-agent workflow visibility
#### Organization Management
* **Smart Creation Dialogs**: When creating new projects or organizations, the name field automatically fills with your current search term, speeding up the creation process
* **Enhanced Search**: Improved search functionality in project and organization dropdowns for more accurate filtering
* **Streamlined Organization Setup**: Added create organization option and "view all workspaces" directly from dropdown menus
## Fixes
No bug fixes in this release.
## Improvements
#### User Experience
* **Keyboard Navigation**: Navigate through trace data using arrow keys when viewing trace details in the popout window
* **Visual Clarity**: Added row highlighting to clearly show which trace is currently open in the detailed view
* **Better Error Handling**: Clear error messages when project creation fails, with automatic navigation to newly created projects on success
#### Performance
* **Faster API Responses**: Enabled Gzip compression for API responses, reducing data transfer sizes and improving load times across the platform
# v0.3 Release Notes (July 29, 2025)
URL: /changelog/v0.03
***
## title: "v0.3 Release Notes (July 29, 2025)"
## New Features
#### Error Investigation Workflow
Click on errors in the dashboard table to automatically navigate to erroneous trace for detailed debugging.
## Fixes
No bug fixes in this release.
## Improvements
No improvements in this release.
## New Features
No new features in this release.
## Fixes
#### Bug fixes and stability improvements
Various bug fixes and stability improvements.
## Improvements
No improvements in this release.
## New Features
#### Client Integrations
* **Groq Client Integration**: Added `wrap()` support for Groq clients with automatic token usage tracking and cost monitoring. [Set up Groq tracing →](https://docs.judgmentlabs.ai/documentation/tracing/introduction#tracing)
#### Enhanced Examples
* **Flexible Example Objects**: Examples now support custom fields, making it easy to define data objects that represent your scenario. [Define custom Examples →](https://docs.judgmentlabs.ai/documentation/evaluation/scorers/custom-scorers#define-your-custom-example-class)
## Fixes
No bug fixes in this release.
## Improvements
#### Performance
* **Faster JSON Processing**: Migrated to orjson for significantly improved performance when handling large datasets and trace data
#### User Experience
* **Smart Navigation**: Automatically redirects you to your most recently used project and organization when logging in or accessing the platform
# v0.4 Release Notes (Aug 1, 2025)
URL: /changelog/v0.04
***
## title: "v0.4 Release Notes (Aug 1, 2025)"
## New Features
#### Enhanced Rules Engine
* **PromptScorer Rules**: Use your PromptScorers as metrics in automated rules, enabling rule-based actions triggered by your custom scoring logic. [Configure rules with PromptScorers →](https://docs.judgmentlabs.ai/documentation/performance/alerts/rules#rule-configuration)
#### Access Control Enhancement
* **New Viewer Role**: Added a read-only role that provides access to view dashboards, traces, evaluation results, datasets, alerts, and other platform data without modification privileges - perfect for stakeholders who need visibility without editing access
#### Data Exporting
* **Trace Export**: Export selected traces from monitoring and dataset tables as JSONL files for external analysis or archival purposes. [Export traces →](https://docs.judgmentlabs.ai/documentation/evaluation/dataset#export-from-platform-ui)
## Fixes
No bug fixes in this release.
## Improvements
#### Data Management
* **Paginated Trace Fetching**: Implemented efficient pagination for viewing large volumes of traces, making it faster to browse and analyze your monitoring data
* **Multi-Select and Batch Operations**: Select multiple tests and delete them in bulk for more efficient test management
#### Evaluation Expected Behavior
* **Consistent Error Scoring**: Custom scorers that encounter errors now automatically receive a score of 0, ensuring clear identification of failed evaluations in your data
#### Developer Experience
* **Enhanced Logging**: Added detailed logging for PromptScorer database operations to help debug and monitor scorer creation and updates
#### User Experience
* **Enhanced Action Buttons**: Improved selection action bars across all tables with clearer button styling, consistent labeling, and better visual hierarchy for actions like delete and export
* **Streamlined API Key Setup**: Copy API keys and organization IDs as pre-formatted environment variables (`JUDGMENT_API_KEY` and `JUDGMENT_ORG_ID`) for faster application configuration
# v0.5 Release Notes (Aug 4, 2025)
URL: /changelog/v0.05
***
## title: "v0.5 Release Notes (Aug 4, 2025)"
## New Features
#### Annotation Queue System
* **Automated Queue Management**: Failed traces are automatically added to an annotation queue for manual review and scoring
* **Human Evaluation Workflow**: Add comments and scores to queued traces, with automatic removal from queue upon completion
* **Dataset Integration**: Export annotated traces to datasets for long-term storage and analysis purposes
#### Enhanced Async Evaluations
* **Sampling Control**: Added sampling rate parameter to async evaluations, allowing you to control how frequently evaluations run on your production data (e.g., evaluate 5% of production traces for hallucinations). [Configure sampling →](https://docs.judgmentlabs.ai/documentation/performance/agent-behavior-monitoring#quickstart)
* **Easier Async Evaluations**: Simplified async evaluation interface to make running evaluations on live traces smoother
#### Local Scorer Execution
* **Local Execution**: Custom scorers for online evaluations now run locally with asynchronous background processing, providing faster evaluation results without slowing down the critical path. [Set up local scorers →](https://docs.judgmentlabs.ai/documentation/performance/agent-behavior-monitoring#using-custom-scorers-with-online-evals)
#### PromptScorer Website Management
* **Platform-Based PromptScorer Creation**: Create, edit, delete, and manage custom prompt-based evaluation scorers with an interactive playground to test configurations in real-time before deployment. [Manage PromptScorers →](https://docs.judgmentlabs.ai/documentation/evaluation/scorers/prompt-scorer#judgment-platform)
## Fixes
No bug fixes in this release.
## Improvements
#### Platform Reliability
* **Improved Data Serialization**: Standardized JSON encoding across the platform using FastAPI's proven serialization methods for more reliable trace data handling and API communication
#### Community Contributions
Special thanks to [@dedsec995](https://github.com/dedsec995) and our other community contributors for helping improve the platform's data serialization capabilities.
# v0.6 Release Notes (Aug 14, 2025)
URL: /changelog/v0.06
***
## title: "v0.6 Release Notes (Aug 14, 2025)"
## New Features
#### Server-Hosted Custom Scorers
* **CLI for Custom Scorer Upload**: New `judgeval` CLI with `upload_scorer` command for submitting custom Python scorer files and dependencies to the backend for hosted execution
* **Hosted vs Local Scorer Support**: Clear differentiation between locally executed and server-hosted custom scorers through the `server_hosted` flag
* **Enhanced API Client**: Updated client with custom scorer upload endpoint and extended timeout for file transfers
#### Enhanced Prompt Scorer Capabilities
* **Threshold Configuration**: Added threshold parameter (0-1 scale) to prompt scorers for defining success criteria with getter functions for controlled access. [Learn about PromptScorers →](https://docs.judgmentlabs.ai/documentation/evaluation/scorers/prompt-scorer)
#### Rules and Custom Scorers
* **Custom Score Rules**: Integration of custom score names in rule configuration for expanded metric triggers beyond predefined options. [Configure rules →](https://docs.judgmentlabs.ai/documentation/performance/alerts/rules)
#### Advanced Dashboard Features
* **Scores Dashboard**: New dedicated dashboard for visualizing evaluation scores over time with comprehensive percentile data tables
* **Rules Dashboard**: Interactive dashboard for tracking rule invocations with detailed charts and statistics
* **Test Comparison Tool**: Side-by-side comparison of test runs with detailed metric visualization and output-level diffing
#### Real-Time Monitoring Enhancements
* **Live Trace Status**: Real-time polling for trace and span execution status with visual indicators for running operations
* **Class Name Visualization**: Color-coded badges for class names in trace spans for improved observability and navigation
## Fixes
No bug fixes in this release.
## Improvements
#### Evaluation System Refinements
* **Simplified API Management**: Evaluation runs now automatically handle result management with unique IDs and timestamps, eliminating the need to manage `append` and `override` parameters
# v0.7 Release Notes (Aug 16, 2025)
URL: /changelog/v0.07
***
## title: "v0.7 Release Notes (Aug 16, 2025)"
## New Features
#### Reinforcement learning now available
Train custom models directly on your own data with our new reinforcement learning framework powered by Fireworks AI. You can now iteratively improve model performance using reward-based learning workflows—capture traces from production, generate training datasets, and deploy refined model snapshots all within Judgment. This makes it easier to build agents that learn from real-world usage and continuously improve over time. [Learn more →](/docs/agent-optimization)
#### Export datasets at scale
Export large datasets directly from the UI for model training or offline analysis. Both example and trace datasets can be exported in multiple formats, making it simple to integrate Judgment data into your ML pipelines or share results with your team
#### Histogram visualization for test results
The test page now displays score distributions using histograms instead of simple averages. See how your scores are distributed across 10 buckets to quickly identify patterns, outliers, and performance trends. This gives you deeper insights into model behavior beyond single average metrics.
#### Faster navigation and better feedback
Navigate between examples using arrow keys (Up/Down), close views with Escape, and get instant feedback with our new toast notification system. We've also added hover cards on table headers that explain metrics like LLM cost calculations. Plus, the Monitoring section now opens directly to your dashboard, getting you to your metrics faster
## Fixes
No bug fixes in this release.
## Improvements
#### More collaborative permissions
Annotation and trace span endpoints are now accessible to Viewers (previously required Developer permissions). This makes it easier for team members to contribute insights and annotations without needing elevated access.
#### Better error handling across the platform
Query timeouts now show clear, actionable error messages instead of generic failures.
#### Polish and refinements
Cost and token badges now appear only on LLM spans, reducing visual clutter. Score details are expandable for deeper inspection of structured data. We've also refreshed the onboarding experience with tabbed code snippets and improved dark mode styling.
# v0.8 Release Notes (Aug 25, 2025)
URL: /changelog/v0.08
***
## title: "v0.8 Release Notes (Aug 25, 2025)"
## New Features
#### Manage custom scorers in the UI
View and manage all your custom scorers directly in the platform. We've added a new tabbed interface that separates Prompt Scorers and Custom Scorers, making it easier to find what you need. Each custom scorer now has a dedicated page where you can view the code and dependencies in read-only format—perfect for team members who want to understand scoring logic without diving into codebases.
#### Track success rates and test history
The Tests dashboard now includes an interactive success rate chart alongside your existing scorer metrics. See how often your tests pass over time and quickly identify regressions. You can also customize the view to show the past 30, 50, or 100 tests, with smart time axis formatting that adjusts based on data density (month/day for sparse data, down to minute/second for high-frequency testing).
#### Better navigation throughout the platform
We've added back buttons to nested pages (Tests, Datasets, Annotation Queue, and Scorers) so you can navigate more intuitively. The sidebar now includes an enhanced support menu that consolidates links to documentation, GitHub, Discord, and support in one convenient dropdown.
## Fixes
#### Registration error handling
Registration now shows clear error messages when you try to use an existing email.
#### Latency chart consistency
Latency charts display consistent units across the Y-axis and tooltips.
## Improvements
#### Enhanced security
Migrated email templates to Jinja2 with autoescaping to prevent HTML injection.
#### Improved trace tables
You can now sort your traces by Name, Created At, Status, Tags, Latency, and LLM Cost.
#### Small platform enhancements
Click outside the trace view popout to dismiss it. Rules interface sections now expand and collapse smoothly, and Slack integration status is clearer with direct links to settings when not connected.
# v0.9 Release Notes (Sep 2, 2025)
URL: /changelog/v0.09
***
## title: "v0.9 Release Notes (Sep 2, 2025)"
### Major Release: OpenTelemetry (OTEL) Integration
We've migrated the entire tracing system to OpenTelemetry, the industry-standard observability framework. This brings better compatibility with existing monitoring tools, more robust telemetry collection, and a cleaner SDK architecture. The SDK now uses auto-generated API clients from our OpenAPI specification, includes comprehensive support for LLM streaming responses, and provides enhanced span management with specialized exporters. This foundation sets us up for deeper integrations with the broader observability ecosystem.
## New Features
#### Trace prompt scorers and evaluation improvements
Evaluate traces using prompt-based scoring with the new [`TracePromptScorer`](/documentation/evaluation/prompt-scorers#trace-prompt-scorers). This enables you to score entire trace sequences based on custom criteria, making it easier to catch complex agent misbehaviors that span multiple operations. We've also added clear separation between example-based and trace-based evaluations with distinct configuration classes, and Examples now automatically generate unique IDs and timestamps.
#### Command palette for faster navigation
Press Cmd+K to open the navigation and search palette. Quickly jump to any page on the platform or search our documentation for answers while using Judgment.
#### Better trace views and UI polish
Trace views now include input/output previews and smoother navigation between traces. Dashboard cards use consistent expand/collapse behavior, annotation tabs show proper empty states, and custom scorer pages display read-only badges when appropriate\*\*\*\*.\*\*\*\*
## Fixes
#### Trace navigation issues
Fixed trace navigation from the first row.
#### UI revalidation after test deletion
Integrated automatic UI revalidation after test deletion.
## Improvements
#### Better LLM streaming support
Token usage and cost tracking now works seamlessly across streaming responses from all major LLM providers, including specific support for Anthropic's `client.messages.stream` method. This ensures accurate cost tracking even when using streaming APIs.
#### Improved skeleton loading states
Improved skeleton loading states to reduce layout shift.
# v0.10 Release Notes (Sep 11, 2025)
URL: /changelog/v0.10
***
## title: "v0.10 Release Notes (Sep 11, 2025)"
## New Features
#### Interactive trace timeline
Visualize trace execution over time with the new interactive timeline view. Zoom in to inspect specific spans, see exact timing relationships between operations, and use the dynamic crosshair to analyze performance bottlenecks. The timeline includes sticky span names and smooth zoom controls, making it easy to understand complex trace hierarchies at a glance.
#### Organize scorers with drag-and-drop groups
Create custom scorer groups and organize them with drag-and-drop functionality. This makes it easier to manage large collections of scorers and better interpret test results.
#### Updated UI Test Run experience
The new Run Test UI provides a cleaner interface for executing test runs and viewing results.
#### Better trace visibility and annotations
Annotation counts now appear directly on trace tables, and individual spans show visual indicators when they have annotations. This makes it easy to see which traces your team has reviewed without opening each one. Trace tables now support and persist column reordering, resizing, and sorting for users.
#### Smarter output display
Output fields now automatically detect and format URLs as clickable links, making it easy to navigate to external resources or related data. Raw content is handled intelligently with better formatting across the platform.
## Fixes
#### OpenTelemetry span attribute serialization
Fixed serialization issues for OpenTelemetry span attributes.
#### Table sorting issues
Corrected table sorting across multiple columns.
#### YAML serialization formatting
Fixed YAML serialization formatting.
#### Score badge overflow
Improved score badge styling to prevent overflow.
## Improvements
#### Faster dashboard queries and data processing
Significantly speed up dashboard loading times using pre-computations. We've also improved fetching and processing large datasets, and expanded SDK compatibility to include Python 3.10.
#### Improve OpenTelemetry support
The OpenTelemetry TracerProvider is now globally registered for consistent distributed tracing. JSON serialization includes robust error handling with fallback to string representation for non-serializable objects.
#### Generator tracing support
Add support for tracing synchronous and asynchronous generator functions with span capture at the yield level, enabling better observability for streaming operations.
#### Enhanced authentication and member management
The login flow now automatically redirects on session expiration and disables buttons during submission to prevent double-clicks. Improved member invitation flows and loading states.
#### Default parameter values for evaluation functions
Added default parameter values for evaluation functions.
# v0.11 Release Notes (Sep 16, 2025)
URL: /changelog/v0.11
***
## title: "v0.11 Release Notes (Sep 16, 2025)"
## New Features
#### Select multiple scorers when creating tests
Test creation now supports selecting multiple scorers at once instead of one at a time. The dialog includes search filtering to quickly find the scorers you need, and the system validates compatibility between your dataset type and selected scorers.
#### Run tests directly from dataset tables
Dataset tables now include action buttons that let you run tests directly from a dataset. No more navigating to the tests page and hunting for the right dataset.
#### Broader OpenTelemetry compatibility
The trace ingestion endpoint now accepts both JSON and Protobuf formats, automatically detecting the content type and parsing accordingly. This expands compatibility with different OpenTelemetry clients and language SDKs beyond just Python.
## Fixes
No bug fixes in this release.
## Improvements
#### Faster, more efficient exports
Trace exports now stream directly to disk instead of buffering in memory, making it possible to download massive datasets without browser memory issues.
#### Better data consistency and validation
Dataset examples now return in consistent chronological order. The `Dataset.add_examples()` method includes type validation to catch incorrect usage of data types earlier. Project activity timestamps now accurately reflect the latest activity across test runs, traces, and datasets.
#### Updated Terms of Use
Replaced the concise Terms of Service with a comprehensive [Terms of Use](https://app.judgmentlabs.ai/terms) document covering Customer Obligations, Customer Data, Fees and Payment Terms, and AI Tools usage. Effective September 4, 2025.
# v0.12 Release Notes (Sep 18, 2025)
URL: /changelog/v0.12
***
## title: "v0.12 Release Notes (Sep 18, 2025)"
## New Features
#### List and manage datasets programmatically
The SDK now includes a `Dataset.list()` method for retrieving all datasets in a project.
#### Better error messages for Agent Behavior Monitoring (ABM) setup
The SDK now validates that you're using the `@observe` decorator when calling `async_evaluate()`, showing clear warning messages if the span context is missing. This catches a common setup mistake early and enables easy fixing.
#### Customize spans with names and attributes
The `@observe` decorator now accepts `span_name` and `attributes` parameters for more granular control over how spans appear in traces. This makes it easier to add custom metadata and organize traces with meaningful names that reflect your agent's structure.
## Fixes
No bug fixes in this release.
## Improvements
#### Visual refinements to trace tree
Icons in the trace tree UI have been moved to the right and connected with elbow connectors, making the hierarchy easier to scan. Minor polish includes adjusted search input heights and cleaner export button styling.
# v0.13 Release Notes (Sep 25, 2025)
URL: /changelog/v0.13
***
## title: "v0.13 Release Notes (Sep 25, 2025)"
## New Features
#### Platform styling refresh
Updated logo assets with unified light and dark mode versions, changed the primary brand color to orange, and sharpened border radius throughout the platform for a more modern appearance. Adjusted spacing in authentication and onboarding flows for better visual consistency.
#### Test and configure trace scorers in the playground
The new trace prompt scorer playground lets you configure and test agent scorers interactively before deploying them. Iterate on your scoring rubric by running multiple versions against each other on production agent data and viewing results immediately.
#### Advanced alert configuration and monitoring
Configure alert action frequency and cooldown periods with precise timing control to avoid alert fatigue. The monitoring dashboard now includes a dedicated alert invocations chart and filter, making it easy to understand why your alerts fire and how to fix underlying issues.
#### Track scorer success rates over time
The new "Scorers Passed" chart visualizes how often your scorers succeed across test runs. The test table includes a "Scorers Passed" column showing success rate and count at a glance, and scorer charts now have interactive legends that let you filter specific score types and focus on what matters.
#### Redesigned settings interface
Settings now use a clean card-based layout with improved navigation and consistent branding. Added a "Back to Platform" button for quick navigation and "Copy organization ID" functionality with visual feedback. The members table includes resizable columns and consolidated dropdowns for a cleaner interface.
## Fixes
No bug fixes in this release.
## Improvements
#### Better chart readability and data interpretation
Time series charts now limit to 10 labels maximum for cleaner display, and average score and latency charts include descriptive Y-axis labels.
#### Prompt scorer interface improvements
Added syntax highlighting for variables and resizable panels in the PromptScorer interface, making it easier to write and iterate complex scoring rubrics.
#### Infinite scroll for large tables
Trace and project tables now use infinite scroll instead of pagination, providing smoother navigation when working with hundreds or thousands of entries.
#### Updated privacy policy
Substantially revised [privacy policy](https://app.judgmentlabs.ai/privacy) with clear sections for Product-Platform and Website interactions. Includes comprehensive coverage of GDPR, CCPA, VCDPA, CPA, and other data protection regulations, with documentation of user rights for access, deletion, correction, and opt-out.
# v0.14 Release Notes (Sep 28, 2025)
URL: /changelog/v0.14
***
## title: "v0.14 Release Notes (Sep 28, 2025)"
## New Features
#### Work with trace datasets in the SDK
The `Dataset` class now supports trace datasets. Use `Dataset.get()` to retrieve trace datasets with full OpenTelemetry structure including spans, scores, and triggered rules. This makes it easy to export production traces for optimization (ie. SFT, DPO, RFT) or create test datasets from real agent executions for sanity checking agent updates.
#### Export datasets and traces
Export datasets and traces for data portability, offline analysis, or integration with external tools. This gives you full control over your evaluation data and production traces.
## Fixes
#### Cumulative cost tracking issues
Fixed issues with cumulative cost tracking for better billing insights.
#### Column rendering in example datasets
Fixed column rendering in example datasets.
## Improvements
#### Accurate, up-to-date LLM cost tracking
LLM costs are now calculated server-side with the latest pricing information, ensuring accurate cost tracking as providers update their rates.
#### Simpler rule configuration
Rules now trigger based on whether scores pass or fail, replacing the previous custom threshold system. This makes it easier to set up alerts without tuning specific score values.
#### Better multimodal content display
Enhanced display for multimodal OpenAI chat completions with proper formatting for images and text. Added fullscreen view for large content with scroll-to-bottom functionality.
#### Configure models per scorer
Trace prompt scorers now include model configuration, making it visible which model evaluates each trace. This gives you more control over scorer quality and cost tradeoffs.
#### Improved form validation
Annotation forms now make comments optional while requiring at least one scorer. Clear error messages and visual indicators guide you when required fields are missing.
#### Performance and visual polish
Optimized keyboard navigation for traces and improved span loading states with better icons.
# Inviting Members
URL: /documentation/access-control/member-invites
How to invite new members to your organization and manage invitations in Judgment Labs.
***
title: Inviting Members
description: "How to invite new members to your organization and manage invitations in Judgment Labs."
------------------------------------------------------------------------------------------------------
## Inviting New Members to Your Organization
To invite new members, you must have an `Owner` or `Admin` role within the organization.
### 1. Go to the Members Settings Page
From any page within your organization, go to `Settings` → `Members`.
### 2. Click "Invite Member"
Click the **Invite Member** button at the top of the members list.

### 3. Fill Out the Invitation Form
A dialog will appear. Enter the email address of the person you want to invite and select their role. You can only invite members to a role with lower privileges than your own.
* Click **Invite** to send the invitation.
### 4. View Pending Invitations
After sending the invite, the pending invitation will appear in the "Pending Invitations" section.

### 5. Invitee Accepts the Invitation
The invitee will receive an email with an invitation link. They should:
* Click the link in the email
* The invitation flow will direct the user to log in if they already have an account, or create a new account if they are new to Judgment Labs
### 6. Member Appears in the Members List
Once the invitee accepts the invitation and logs in, they will appear in the members list for the organization.

### 7. Editing Member Roles
Admins can edit a member's role by clicking the user settings icon in the `Actions` column. You can only assign roles with lower privileges than your own.
***
## Member Roles Explained
Judgment Labs organizations support four roles for members:
### Owner
* **Full access** to all organization settings, members, and data.
* Can invite, remove, and change roles for other members, including admins.
* Can manage billing and notifications for the organization.
* One owner per organization.
### Admin
* **Full access** to all organization settings, members, and data.
* Can invite, remove, and change roles for other members except for other admins and owners.
* Can manage billing and notifications for the organization.
### Developer
* **Access to most project features** such as creating and editing traces, datasets, and tests.
* Cannot manage organization-level settings, billing, or member roles.
* Cannot delete resources or change the name of the organization.
### Viewer
* **Read-only access** to organization data and resources.
* Can view existing traces, datasets, and tests.
* Cannot create, edit, or delete any resources, nor manage members or organization-level settings.
Seat Limit Notice:
- The Free organization plan allows only 3 members per organization.
- The Pro organization plan allows up to 10 seats per organization.
- To increase your seat limit beyond 10, please contact us at [contact@judgmentlabs.ai](mailto:contact@judgmentlabs.ai) to upgrade to a Startup or Enterprise organization plan.
# Why Evaluate AI Agents?
URL: /documentation/concepts/agents
Understanding why Evaluation is Essential for Non-Determinstic and Stateful AI Agents
***
title: Why Evaluate AI Agents?
description: Understanding why Evaluation is Essential for Non-Determinstic and Stateful AI Agents
--------------------------------------------------------------------------------------------------
**This page breaks down theoretical concepts of agent evaluation.**
To get started with actually running evals, check out our [evaluation section](/evaluation/introduction)!
## AI Agent Evaluation
AI agents are **non-deterministic** and **stateful** systems that present unique evaluation challenges:
**Non-deterministic behavior** means agents make dynamic decisions at each step:
* Which tools to call from available options
* When to retrieve or update memory
* How to route between different execution paths
**Stateful behavior** means agents maintain and evolve context over time:
* **Short-term memory**: Conversation history and task context within a session
* **Long-term memory**: User preferences, past interactions, and learned patterns across sessions
Building reliable AI agents is hard because of the brittle, non-deterministic multi-step nature of their executions.
Poor upstream decisions can lead to downstream failures, so any agent component **changes can have a cascading effect on the agent's behavior**.
Agents have increased complexity because they must plan their execution, select the proper tools, and execute them in an order that is both efficient and effective.
They must also reason over their state using memory and retrieval to make meaningful decisions on their execution path based on new information.
To evaluate agents, we must collect the agent's interaction data with customers and run task-specific evals to score the agent's behavior with customer interactions.
## Agent Planning
When an agent receives a query, it must first determine what to do.
One way is to ask it every time — use the LLM to act based on its inputs and memory.
This planning architecture is quite flexible. Sometimes it is also built using hardcoded rules.
To evaluate a planner, we need to check whether it is **selecting the correct next nodes**.
Agents can call tools, invoke other agents, or respond directly, so different branching paths should be accounted for.
You will need to consider cases such as:
* Does the plan include only agents/tools that are valid/available?
* Single turn vs. multi-turn conversation pathways
* Edge cases where the query doesn't match any available tools or actions
* Priority-based routing when multiple tools could handle the same request
## Tool Calling
Tool calling forms the core of agentic behavior, enabling LLMs to interact with the world via external APIs/processes,
self-written functions, and invoke other agents. However, the flexibility of tool calling introduces **failure points in the
tool selection, parameter choice, and tool execution itself**.
To evaluate tool calling, we need to check whether the agent is selecting the correct tools and parameters, as well as
whether the tool is executed successfully.
You should consider cases such as:
* No functions should be called, one function should be called, multiple functions should be called
* Handling failed tool calls (e.g. 404, 422) vs. successful tool calls (200)
* Vague parameters in query vs. specific parameters in the query
* Single turn vs. multi-turn tool calling
## Agent Abilities
Abilities are specialized **capabilities or modules that extend the agent's base functionality**.
They can be implemented as internal functions, scripts, or even as wrappers around tool-calls, but are often more tightly integrated into the agent's architecture.
Examples of abilities include SQL query generation, RAG, summarization, or custom logic like extracting all dates from a text.
Flowchart of abilities for a travel agent's itinerary generation trajectory.
An agent might have abilities that call external services or run locally as functions.
Agents typically use them during reasoning or planning, selecting which abilities to use based on its internal rules.
## Agent Memory
Agent memory enables agents to retain and recall information during an interaction or across multiple trajectories.
This can include user preferences, task-specific tips, or past successful runs that can help performance.
Memory is directly embedded in the agent's context and can either remain static or be updated via retrieval methods at each step in its path.
Agents can peform CRUD operations on memory during the course of an interaction.
Each of these operations influences the agent's behavior and should be monitored and evaluated independently.
Tracking memory read/write operations can help you understand how your agent uses memory in response to
edge cases and familiar tasks.
You should consider test/eval cases such as:
* Does your agent update its memory in response to new information?
* Does your agent truncate its memory when redundant or irrelevant information is logged?
* How much of the active agent memory is relevant to the current task/interaction?
* Does the current context contradict the agent's previous trajectories and memories?
## Agentic Reflection
After a subtask is complete or a response is generated, it can be helpful to query the agent to reflect on the output and whether it accomplished its goal.
If it failed, the agent can re-attempt the task using new context informed by its original mistakes.
In practice, reflection can be accomplished through self-checking, but a common approach is to use a runtime evaluation system (which can itself be an agent) rather than post-hoc analysis.
# Building Useful Evaluations for AI Agents
URL: /documentation/concepts/evaluation
How to build effective evaluations for AI agents to measure behavior and improve their performance
***
title: Building Useful Evaluations for AI Agents
description: How to build effective evaluations for AI agents to measure behavior and improve their performance
---------------------------------------------------------------------------------------------------------------
import { Hammer } from 'lucide-react'
**This page breaks down theoretical concepts of agent evaluation.**
To get started with actually running evals, check out our [evaluation docs](/documentation/evaluation/introduction)!
AI engineers can make countless tweaks to agent design, but **how do they know which changes actually improve agent performance?**
Every prompt change, tool addition, and model selection can significantly impact agent quality—either for better or worse.
**Evals help AI engineers assess the impacts of their changes** and have emerged as the **new CI standard for agents**.
## Decide what to measure
In most cases, the best evaluation targets are the pain points that appear most frequently—or most severely—in your agent's behavior.
These often fall into one of three categories:
**Correctness**: Is the agent producing factually accurate or logically sound responses?
**Goal completion**: Is the agent successfully completing the task it was designed to handle?
**Task alignment**: Is the agent following instructions, using tools appropriately, or responding in a way that's helpful and contextually aware?
If you're not sure where to start, pick a key use case or common user flow and think about what success (or failure) may look like, then try to define measurable properties that capture the outcome.
## Select your eval metrics
Once you've identified the behaviors that matter, you can **design custom evals** that surface meaningful signals on those behaviors.
### Eval Variants
Generally, there are three types of evaluation mechanisms—`LLM judge` and `annotations`.
| Eval Type | How it works | Use cases |
| ---------------- | -------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **LLM-as-judge** | Uses a LLM or system of agents, orchestrated in code, to evaluate and score outputs based on a criteria. | Great for subjective quality or well-defined objective assessments (tone, instruction adherence, hallucination).
Poor for vague preference or subject-matter expertise. |
| **Annotations** | Humans provide custom labels on agent traces. | Great for subject matter expertise, direct application feedback, and "feels right" assessments.
Poor for large scale, cost-effective, or time-sensitive evaluations. |
### Building your own evals
Perhaps you're working in a novel domain, have unique task definitions, or need to
evaluate agent behavior against proprietary rules. In these cases, building your own evals is the best way to
ensure you're measuring what matters.
Judgment's custom evals module allows you to define:
* What counts as a success or failure, using your own criteria.
* What data to evaluate—a specific step or an entire agent trajectory.
* Whether to score results via heuristics, LLM-as-a-judge, or human annotation.
In `judgeval`, you can build custom evals via:
[Custom Scorers](/documentation/evaluation/scorers/custom-scorers): powerful & flexible, define your own scoring logic in code, with LLMs, or a combination of both.
[Prompt Scorers](/documentation/evaluation/scorers/prompt-scorers): lightweight, simple LLM-as-judge scorers that classify outputs according to natural language criteria.
## What should I use evals for?
Once you've selected or built your evals, you can use them to accomplish many different goals.
| Use Case | Why Use Evals This Way? |
| ------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Online Evals** | Continuously track agent performance in real-time to alert on quality degradation, unusual patterns, or system failures and take automated actions. |
| **A/B Testing** | Compare different agent versions or configurations to make data-driven decisions about which approach performs better on your key metrics. See how your agent is improving (or regressing) over time. |
| **Unit Testing** | Catch regressions early in development by testing specific agent behaviors against predefined tasks. Ensures code changes (e.g. prompt, tool, model updates) don't break existing functionality. |
| **Optimization Datasets** | Create high-quality post-training data by using evals to filter and score agent outputs, which can then be used for fine-tuning or reinforcement learning.
For instance, you can separate successful and failed agent traces to create datasets for supervised and reinforcement learning. |
## Learn more
To learn more about implementing evals in `judgeval`, check out some of our other docs on:
* [Online Evals](/documentation/performance/agent-behavior-monitoring)
* [Unit Testing](/documentation/evaluation/unit-testing)
* [Custom Scorers](/documentation/evaluation/scorers/custom-scorers)
* [Prompt Scorers](/documentation/evaluation/scorers/prompt-scorers)
For a deep dive into evals, check out our feature section for [evaluation](/documentation/evaluation/introduction).
# Agent Behavior Monitoring (ABM)
URL: /documentation/concepts/monitoring
Monitoring agent behavior when interacting with customers in production
***
title: Agent Behavior Monitoring (ABM)
description: "Monitoring agent behavior when interacting with customers in production"
--------------------------------------------------------------------------------------
import { Code } from "lucide-react"
**This page breaks down theoretical concepts of agent behavior monitoring (ABM).**
To get started with actually monitoring your agents, check out our [monitoring docs](/documentation/performance/agent-behavior-monitoring)!
When you're ready to deploy your agent, you need to be able to monitor its actions.
While development and testing help catch many issues, the unpredictable nature of user inputs and non-deterministic agent behavior means that regressions are inevitable in production.
This is where monitoring becomes crucial - it's a window into how your agents interact with users,
the most valuable data for improving your system.
Monitoring your agents helps you:
Track tool-use across your agent fleet in production, understanding how people use your system.
Catch and debug errors in real-time as they impact your customers, enabling quick response to issues.
Ensure system reliability by identifying patterns and risks before they affect multiple users.
## Key Areas to Monitor
Collect agent telemetry in 30 seconds} href="/documentation/tracing/introduction" icon={
| Attribute |
Type |
Description |
Default |
| name |
str |
The name of your scorer to be displayed on the Judgment platform. |
"Custom" |
| score |
float |
The score of the scorer. |
N/A |
| threshold |
float |
The threshold for the scorer. |
0.5 |
| reason |
str |
A description for why the score was given. |
N/A |
| error |
str |
An error message if the scorer fails. |
N/A |
| additional\_metadata |
dict |
Additional metadata to be added to the scorer |
N/A |
### Define your Custom Example Class
You can create your own custom Example class by inheriting from the base Example object. This allows you to configure any fields you want to score.
```py title="custom_example.py"
from judgeval.data import Example
class CustomerRequest(Example):
request: str
response: str
example = CustomerRequest(
request="Where is my package?",
response="Your package will arrive tomorrow at 10:00 AM.",
)
```
### Implement the `a_score_example(){:py}` method
The `a_score_example(){:py}` method takes an `Example` object and executes your scorer asynchronously to produce a `float` (between 0 and 1) score.
Optionally, you can include a reason to accompany the score if applicable (e.g. for LLM judge-based scorers).
The only requirement for `a_score_example(){:py}` is that it:
* Take an `Example` as an argument
* Returns a `float` between 0 and 1
You can optionally set the `self.reason` attribute, depending on your preference.
This method is the core of your scorer, and you can implement it in any way you want. **Be creative!**
```py title="example_scorer.py"
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
# This is using the CustomerRequest class we defined in the previous step
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
score = await scoring_function(example.request, example.response)
self.reason = justify_score(example.request, example.response, score)
return score
```
### Implementation Example
Here is a basic implementation of implementing a ExampleScorer.
```py title="happiness_scorer.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
example = CustomerRequest(
request="Where is my package?",
response="Your package will arrive tomorrow at 10:00 AM."
)
res = client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
)
```
## Next Steps
Ready to use your custom scorers in production? Learn how to monitor agent behavior with online evaluations.
Use Custom Scorers to continuously evaluate your agents in real-time production environments.
# Datasets
URL: /documentation/evaluation/datasets
***
## title: Datasets
import { Database } from "lucide-react"
Datasets group multiple [examples](/sdk-reference/data-types/core-types#example) for scalable evaluation workflows. Use the `Dataset` class to manage example collections, run batch evaluations, and sync your test data with the Judgment platform for team collaboration.
## Quickstart
You can use the `JudgmentClient` to evaluate a collection of `Example`s using scorers.
```py title="evaluate_dataset.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
from judgeval.dataset import Dataset
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
examples = [
CustomerRequest(request="Where is my package?", response="Your P*CKAG* will arrive tomorrow at 10:00 AM."), # failing example
CustomerRequest(request="Where is my package?", response="Your package will arrive tomorrow at 10:00 AM.") # passing example
]
# Create dataset which is automatically saved to Judgment platform
Dataset.create(name="my_dataset", project_name="default_project", examples=examples)
# Fetch dataset from Judgment platform
dataset = Dataset.get(name="my_dataset", project_name="default_project")
res = client.run_evaluation(
examples=dataset.examples,
scorers=[ResolutionScorer()],
project_name="default_project"
)
```
## Creating a Dataset
Datasets can be created by passing a list of examples to the `Dataset` constructor.
```py title="dataset.py"
from judgeval.data import Example
from judgeval.dataset import Dataset
class CustomerRequest(Example):
request: str
response: str
examples = [
CustomerRequest(request="Where is my package?", response="Your P*CKAG* will arrive tomorrow at 10:00 AM.")
]
dataset = Dataset.create(name="my_dataset", project_name="default_project", examples=examples)
```
You can also add `Example`s to an existing `Dataset`.
```py
new_examples = [CustomerRequest(request="Where is my package?", response="Your package will arrive tomorrow at 10:00 AM.")]
dataset.add_examples(new_examples)
```
We automatically save your `Dataset` to the Judgment Platform when you create it and when you append to it.
## Loading a Dataset
### From the Platform
Retrieve datasets you've already saved to the Judgment platform:
```py title="load_from_platform.py"
from judgeval.dataset import Dataset
# Get an existing dataset
dataset = Dataset.get(name="my_dataset", project_name="default_project")
```
### From Local Files
Import datasets from JSON or YAML files on your local machine:
Your JSON file should contain an array of example objects:
```json title="examples.json"
[
{
"input": "Where is my package?",
"actual_output": "Your package will arrive tomorrow."
},
{
"input": "How do I return an item?",
"actual_output": "You can return items within 30 days."
}
]
```
Load the JSON file into a dataset:
```py title="load_json.py"
from judgeval.dataset import Dataset
# Create new dataset and add examples from JSON
dataset = Dataset.create(name="my_dataset", project_name="default_project")
dataset.add_from_json("/path/to/examples.json")
```
Your YAML file should contain a list of example objects:
```yaml title="examples.yaml"
- input: "Where is my package?"
actual_output: "Your package will arrive tomorrow."
expected_output: "Your package will arrive tomorrow at 10:00 AM."
- input: "How do I return an item?"
actual_output: "You can return items within 30 days."
expected_output: "You can return items within 30 days of purchase."
```
Load the YAML file into a dataset:
```py title="load_yaml.py"
from judgeval.dataset import Dataset
# Create new dataset and add examples from YAML
dataset = Dataset.create(name="my_dataset", project_name="default_project")
dataset.add_from_yaml("/path/to/examples.yaml")
```
### Saving Datasets to Local Files
Export your datasets to local files for backup or sharing:
```py title="export_dataset.py"
from judgeval.dataset import Dataset
dataset = Dataset.get(name="my_dataset", project_name="default_project")
# Save as JSON
dataset.save_as("json", "/path/to/save/dir", "my_dataset")
# Save as YAML
dataset.save_as("yaml", "/path/to/save/dir", "my_dataset")
```
## Exporting Datasets
You can export your datasets from the Judgment Platform UI for backup purposes, sharing with team members, or publishing to HuggingFace Hub.
### Export to HuggingFace
You can export your datasets directly to HuggingFace Hub by configuring the `HUGGINGFACE_ACCESS_TOKEN` secret in your organization settings.
**Steps to set up HuggingFace export:**
1. Navigate to your organization's \[Settings > Secrets]
2. Find the `HUGGINGFACE_ACCESS_TOKEN` secret and click the edit icon
3. Enter your HuggingFace access token
4. Once configured, navigate to your dataset in the platform
5. Click the "Export Dataset to HF" button in the top right to export your dataset to HuggingFace Hub

You can generate a HuggingFace access token from your [HuggingFace settings](https://huggingface.co/settings/tokens). Make sure the token has write permissions to create and update datasets.
# Introduction to Agent Scorers
URL: /documentation/evaluation/introduction
How to build and use scorers to track agent behavioral regressions
***
title: Introduction to Agent Scorers
description: "How to build and use scorers to track agent behavioral regressions"
---------------------------------------------------------------------------------
**Agent behavior rubrics** are scorers that measure how your AI agents behave and perform in production.
## Quickstart
Build and iterate on your agent behavior rubrics to measure how your agents perform across specific behavioral dimensions:
```py title="custom_rubric.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
# Define your own data structure
class QuestionAnswer(Example):
question: str
answer: str
# Create your behavioral rubric
class AccuracyScorer(ExampleScorer):
name: str = "Accuracy Scorer"
async def a_score_example(self, example: QuestionAnswer):
# Custom scoring logic for agent behavior
# You can import dependencies, combine LLM judges with logic, and more
if "washington" in example.answer.lower():
self.reason = "Answer correctly identifies Washington"
return 1.0
else:
self.reason = "Answer doesn't mention Washington"
return 0.0
# Test your rubric on examples
test_examples = [
QuestionAnswer(
question="What is the capital of the United States?",
answer="The capital of the U.S. is Washington, D.C."
),
QuestionAnswer(
question="What is the capital of the United States?",
answer="I think it's New York City."
)
]
# Test your rubric
results = client.run_evaluation(
examples=test_examples,
scorers=[AccuracyScorer()],
project_name="default_project"
)
```
Results are automatically saved to your project on the [Judgment platform](https://app.judgmentlabs.ai) where you can analyze performance across different examples and iterate on your rubrics.
Evals in `judgeval` consist of three components:
[`Example`](/sdk-reference/data-types/core-types#example) objects contain the fields involved in the eval.
[`Scorer`](/documentation/evaluation/scorers/introduction) objects contain the logic to score agent executions using code + LLMs or natural language scoring rubrics.
A model, if you are using LLM as a judge, that can be used to score your agent runs.
You can use any model, including finetuned custom models, as a judge.
## Why use behavioral rubrics?
**Agent behavior drifts** as models evolve and new customer use cases emerge. Without systematic monitoring, you'll discover failures after customers complain e.g. support agent hallucinating product information or recommending a competitor.
Build behavioral rubrics based on actual failure patterns you observe in your [agent traces](/documentation/performance/online-evals).
Start by analyzing production errors to identify the critical behavioral dimensions for your use case instead of generic metrics.
Run these [scorers in production](/documentation/performance/online-evals) to detect agent misbehavior, get [instant alerts](/documentation/performance/alerts), and push fixes quickly while easily surfacing your agents' failure patterns for analysis.
## Next steps
Code-defined scorers using any LLM or library dependency
LLM-as-a-judge scorers defined by custom rubrics on the platform
Use scorers to monitor your agents performance in production.
# Prompt Scorers
URL: /documentation/evaluation/prompt-scorers
***
## title: Prompt Scorers
A `PromptScorer` is a powerful tool for scoring your LLM system using easy-to-make natural language rubrics.
You can create a `PromptScorer` on the [SDK](/documentation/evaluation/scorers/prompt-scorers#judgeval-sdk) or the [Judgment Platform](/documentation/evaluation/scorers/prompt-scorers#judgment-platform).
## Quickstart
Under the hood, prompt scorers are the same as any other scorer in `judgeval`. They can be run in conjunction with other scorers in a single evaluation run!
Create the prompt scorer, define your custom fields, and run the prompt scorer online within your LLM system:
```py title="run_prompt_scorer.py"
from judgeval.tracer import Tracer
from judgeval.data import Example
from judgeval.scorers import PromptScorer
judgment = Tracer(project_name="prompt_scorer_test_project")
relevance_scorer = PromptScorer.create(
name="Relevance Scorer",
# define any variables you want to use from your custom example object with {{var}}
prompt="Is the request relevant to the response? Request: {{request}}\n\nResponse: {{response}}",
options={"Yes": 1, "No": 0}
)
class CustomerRequest(Example): # define your own data structure
request: str
response: str
@judgment.observe(span_type="tool")
def llm_call(request: str):
response = "Your package will arrive tomorrow at 10:00 AM." # replace with your LLM calls
example = CustomerRequest(request=request, response=response)
judgment.async_evaluate(scorer=relevance_scorer, example=example, model="gpt-5") # execute the scoring
return response
@judgment.observe(span_type="function")
def main():
request = "Where is my package?"
response = llm_call(request)
if __name__ == "__main__":
main()
```
For more detailed information about using `PromptScorer` in the `judgeval` SDK, refer to the [SDK reference](https://docs.judgmentlabs.ai/sdk-reference/prompt-scorer).
## `judgeval` SDK deep dive
### Create a Prompt Scorer
You can create a `PromptScorer` by providing a `prompt` that describes the evaluation criteria and
a set of choices that an LLM judge can choose from when evaluating an example.
You can also use custom fields in your `prompt` by using the mustache `{{variable_name}}` syntax! Read how to do this in the section [below](#define-custom-fields).
Here's an example of creating a `PromptScorer` that determines if a response is relevant to a request:
```py title="prompt_scorer.py"
from judgeval.scorers import PromptScorer
relevance_scorer = PromptScorer.create(
name="Relevance Scorer",
prompt="Is the request relevant to the response? The request is {{request}} and the response is {{response}}."
)
```
#### Options
You can also provide an `options` dictionary where you can specify possible choices for the scorer and assign scores to these choices.
Here's an example of creating a `PromptScorer` that determines if a response is relevant to a request, with the options dictionary:
```py title="prompt_scorer.py"
from judgeval.scorers import PromptScorer
relevance_scorer = PromptScorer.create(
name="Relevance Scorer",
prompt="Is the request relevant to the response? The request is {{request}} and the response is {{response}}.",
options={"Yes" : 1, "No" : 0}
)
```
### Retrieving a Prompt Scorer
Once a Prompt Scorer has been created, you can retrieve the prompt scorer by name using the `get` class method for the Prompt Scorer. For example, if you had already created the Relevance Scorer from above, you can fetch it with the code below:
```py title="prompt_scorer.py"
from judgeval.scorers import PromptScorer
relevance_scorer = PromptScorer.get(
name="Relevance Scorer",
)
```
### Edit Prompt Scorer
You can also edit a prompt scorer that you have already created. You can use the methods `get_name`, `get_prompt`, and `get_options` to get the fields corresponding to the scorer you created. You can update fields with the `set_prompt`, `set_options`, and `set_threshold` methods.
In addition, you can add to the prompt using the `append_to_prompt` field.
```py title="edit_scorer.py"
from judgeval.scorers import PromptScorer
relevancy_scorer = PromptScorer.get(
name="Relevance Scorer",
)
# Adding another sentence to the relevancy scorer prompt
relevancy_scorer.append_to_prompt("Consider whether the response directly addresses the main topic, intent, or question presented in the request.")
# Make additions to options by using the get function and the set function
options = relevancy_scorer.get_options()
options["Maybe"] = 0.5
relevancy_scorer.set_options(options)
# Set threshold for success for the scorer
relevancy_scorer.set_threshold(0.7)
```
### Define Custom Fields
You can create your own custom fields by creating a custom data structure which inherits from the base `Example` object. This allows you to configure any fields you want to score.
For example, to use the relevance scorer from [above](#options), you would define a custom Example object with `request` and `response` fields.
```py title="custom_example.py"
from judgeval.data import Example
class CustomerRequest(Example):
request: str
response: str
example = CustomerRequest(
request="Where is my package?",
response="Your package will arrive tomorrow at 10:00 AM.",
)
```
### Using a Prompt Scorer
Prompt scorers can be used in the same way as any other scorer in `judgeval`.
They can also be run in conjunction with other scorers in a single evaluation run!
Putting it all together, you can retrieve a prompt scorer, define your custom fields, and run the prompt scorer within your agentic system like below:
```py title="run_prompt_scorer.py"
from judgeval.tracer import Tracer
from judgeval.data import Example
from judgeval.scorers import PromptScorer
judgment = Tracer(project_name="prompt_scorer_test_project")
relevance_scorer = PromptScorer.get( # retrieve scorer
name="Relevance Scorer"
)
# define your own data structure
class CustomerRequest(Example):
request: str
response: str
@judgment.observe(span_type="tool")
def llm_call(request: str):
response = "Your package will arrive tomorrow at 10:00 AM." # replace with your LLM calls
example = CustomerRequest(request=request, response=response)
# execute the scoring
judgment.async_evaluate(
scorer=relevance_scorer,
example=example,
model="gpt-4.1"
)
return response
@judgment.observe(span_type="function")
def main():
request = "Where is my package?"
response = llm_call(request)
print(response)
if __name__ == "__main__":
main()
```
For more detailed information about using `PromptScorer` in the `judgeval` SDK, refer to the [SDK reference](/sdk-reference/prompt-scorer).
## Trace Prompt Scorers
A `TracePromptScorer` is a special type of prompt scorer which runs on a full trace or subtree of a trace rather than on an `Example` or custom `Example`. You can use a `TracePromptScorer` if you want your scorer to have multiple trace spans as context for the LLM judge.
### Creating a Trace Prompt Scorer
Creating a Trace Prompt Scorer is very similar to defining a Prompt Scorer. Since it is not evaluated over an `Example` object, there is no need to have any of the placeholders with mustache syntax as required for a regular `PromptScorer`.
The syntax for creating, retrieving, and editing the scorer is otherwise identical to the `PromptScorer`.
```py title="trace_prompt_scorer.py"
from judgeval.scorers import TracePromptScorer
trace_scorer = TracePromptScorer.create(
name="Trace Scorer",
prompt="Does the trace contain a reference to store policy on returning items? (Y/N)"
)
```
### Running a Trace Prompt Scorer
Running a trace prompt scorer can be done through the [`observe`](/sdk-reference/tracing#tracerobservepy) decorator.
You will need to make a [`TraceScorerConfig`](/sdk-reference/tracing#tracescorerconfigpy) object and pass in the `TracePromptScorer` into the object.
The span that is observed and all children spans will be given to the LLM judge.
Putting it all together, you can run your trace prompt scorer within your agentic system like below:
```py
from judgeval.tracer import Tracer, TraceScorerConfig
from judgeval.scorers import TracePromptScorer
judgment = Tracer(project_name="prompt_scorer_test_project")
# Retrieve the scorer
trace_scorer = TracePromptScorer.get(
name="Trace Scorer"
)
@judgment.observe(span_type="function")
def sample_trace_span(sample_arg):
print(f"This is a sample trace span with sample arg {sample_arg}")
@judgment.observe(span_type="function", scorer_config=TraceScorerConfig(scorer=trace_scorer, model="gpt-5"))
def main():
sample_trace_span("test")
if __name__ == "__main__":
main()
```
## Judgment Platform
You can also create and manage prompt scorers purely through the Judgment Platform.
Get started by navigating to the **Scorers** tab in the Judgment platform. You'll find this via the sidebar on the left. Ensure you are on the `PromptScorer` section.
Here, you can manage the prompt scorers that you have created. You can also create new prompt scorers.
### Creating a Scorer
1. Click the **New PromptScorer** button in the top right corner. Enter in a name, select the type of scorer, and hit the **Next** button to go to the next page.
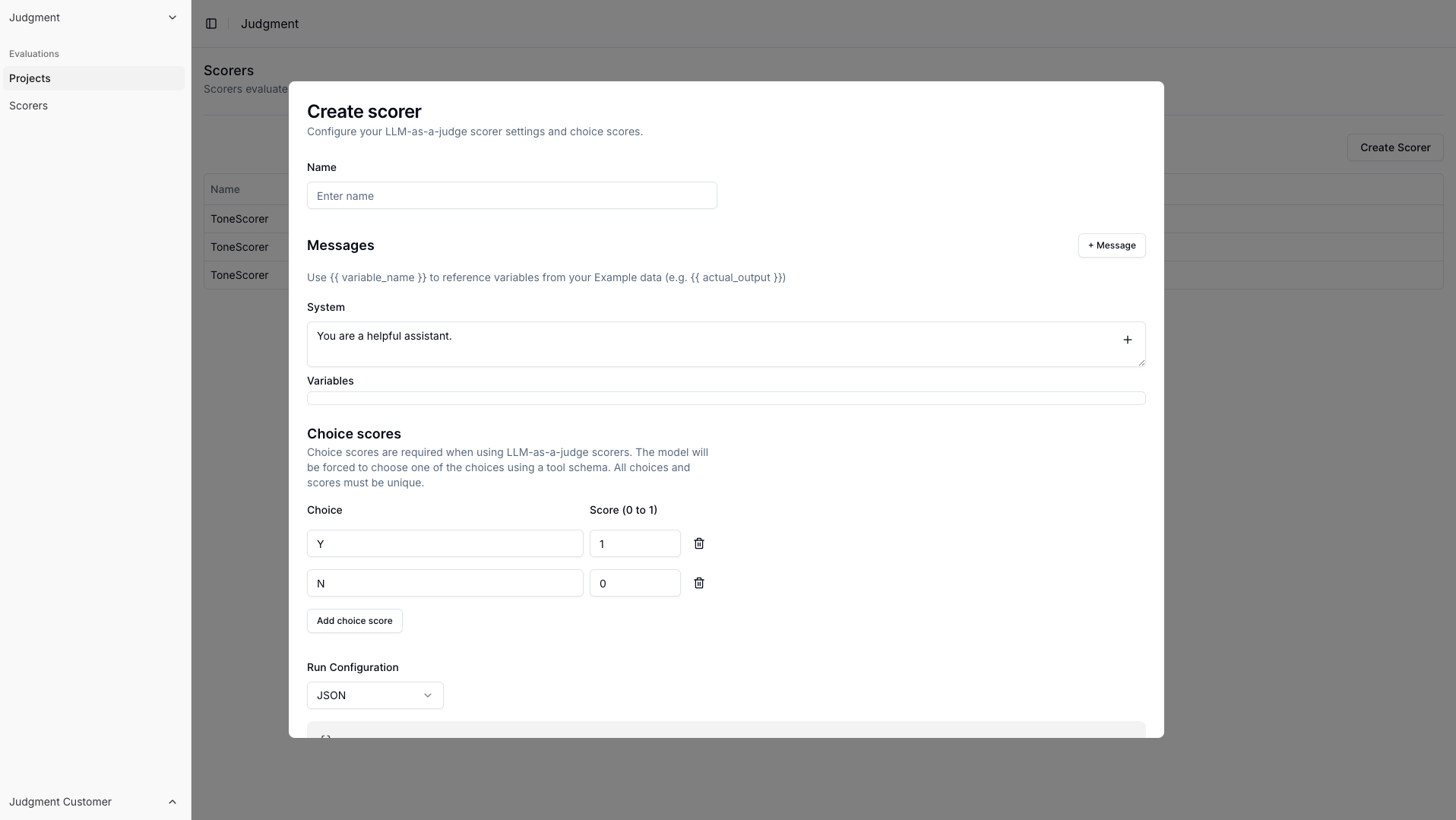
2. On this page, you can create a prompt scorer by using a criteria in natural language, supplying your custom fields from your custom Example class. In addition, add the threshold needed for the score returned by the LLM judge to be considered a success
Then, you can optionally supply a set of choices the scorer can select from when evaluating an example. Once you provide these fields, hit the `Create Scorer` button to finish creating your scorer!
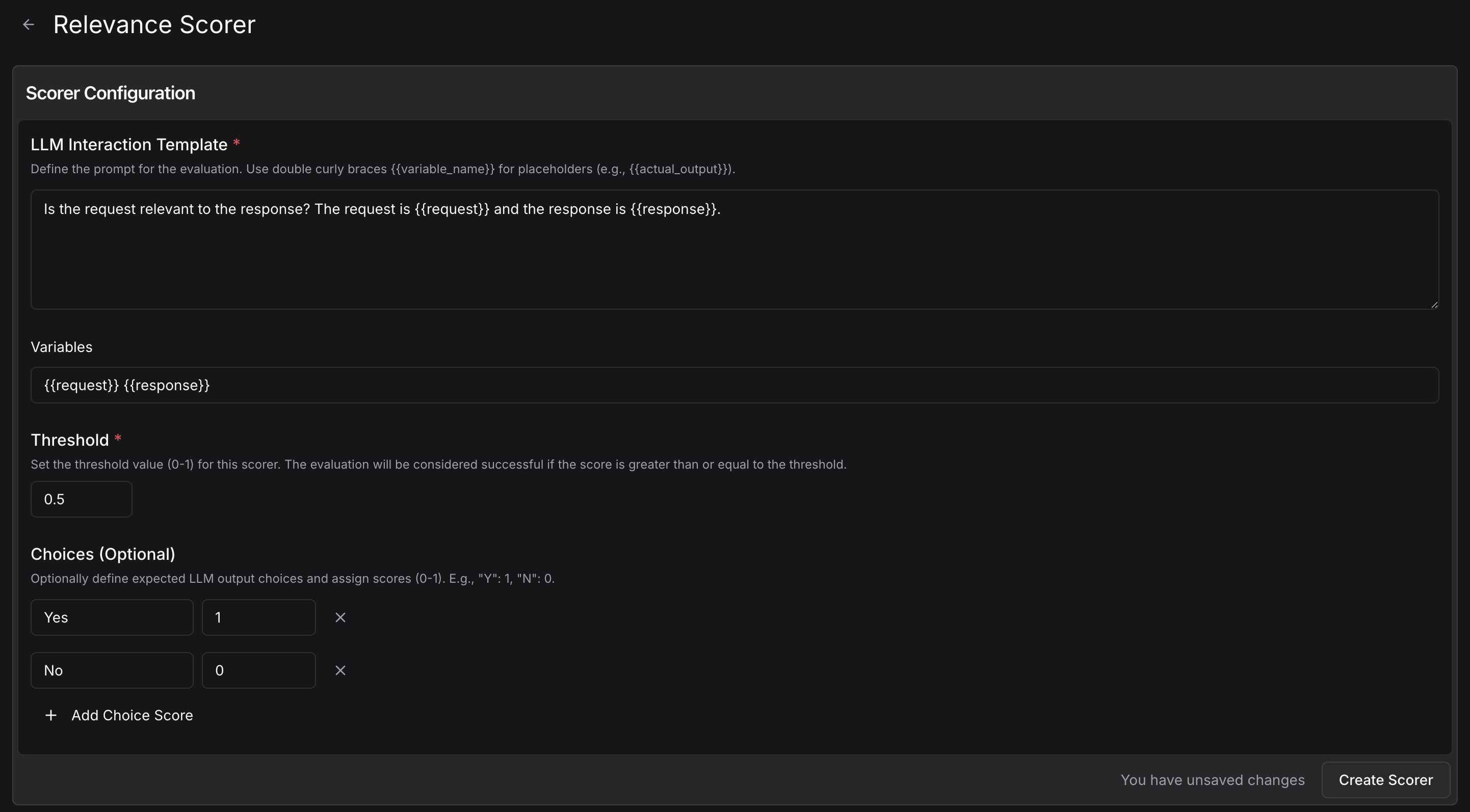
You can now use the scorer in your evaluation runs just like any other scorer in `judgeval`.
### Scorer Playground
While creating a new scorer or editing an existing scorer, it may be helpful to get a general sense of what your scorer is like. The scorer playground helps you test your `PromptScorer` with custom inputs.
When on the page for the scorer you would like to test, select a model from the dropdown and enter in custom inputs for the fields. Then click on the **Run Scorer** button.
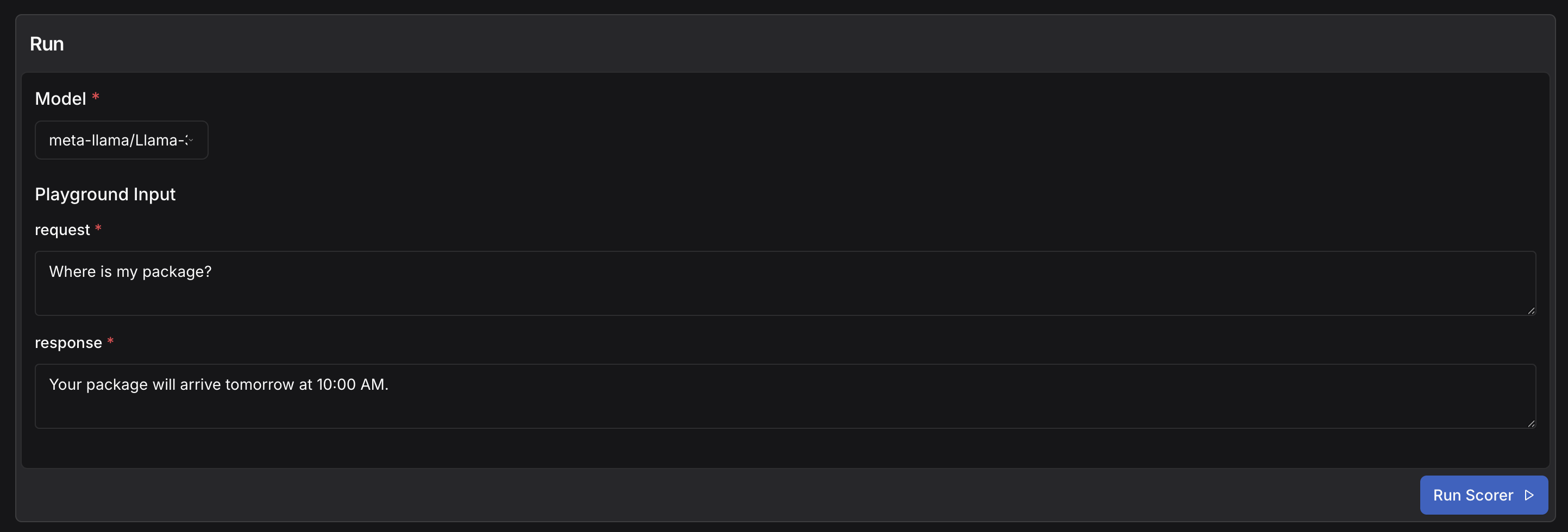
Once you click on the button, the LLM judge will run an evaluation. Once the evaluation results are ready, you will be able to see the score, reason, and choice given by the judge.

## Next Steps
Ready to use your custom scorers in production? Learn how to monitor agent behavior with online evaluations.
Use Custom Scorers to continuously evaluate your agents in real-time production environments.
# Regression Testing
URL: /documentation/evaluation/regression-testing
Use evals as regression tests in your CI pipelines
***
title: Regression Testing
description: "Use evals as regression tests in your CI pipelines"
-----------------------------------------------------------------
import { Braces } from "lucide-react"
`judgeval` enables you to unit test your agent against predefined tasks/inputs, with built-in support for common
unit testing frameworks like [`pytest`](https://docs.pytest.org/en/stable/).
## Quickstart
You can formulate evals as unit tests by checking if [scorers](/documentation/evaluation/scorers/introduction) **exceed or fall below threshold values**
on a set of [examples](/sdk-reference/data-types/core-types#example) (test cases).
Setting `assert_test=True` in `client.run_evaluation()` runs evaluations as unit tests, raising an exception if the score falls below the defined threshold.
```py title="unit_test.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
example = CustomerRequest(request="Where is my package?", response="Your P*CKAG* will arrive tomorrow at 10:00 AM.")
res = client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
assert_test=True
)
```
If an example fails, the test will report the failure like this:
================================================================================
⚠️ TEST RESULTS: 0/1 passed (1 failed)
================================================================================
✗ Test 1: FAILED
Scorer: Resolution Scorer
Score: 0.0
Reason: The response does not contain the word 'package'
----------------------------------------
================================================================================
Unit tests are treated as evals and the results are saved to your projects on the [Judgment platform](https://app.judgmentlabs.ai):
## Pytest Integration
`judgeval` integrates with `pytest` so you don't have to write any additional scaffolding for your agent unit tests.
We'll reuse the code above and now expect a failure with pytest by running `uv run pytest unit_test.py`:
```py title="unit_test.py"
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
from judgeval.exceptions import JudgmentTestError
import pytest
client = JudgmentClient()
class CustomerRequest(Example):
request: str
response: str
class ResolutionScorer(ExampleScorer):
name: str = "Resolution Scorer"
async def a_score_example(self, example: CustomerRequest):
# Replace this logic with your own scoring logic
if "package" in example.response:
self.reason = "The response contains the word 'package'"
return 1
else:
self.reason = "The response does not contain the word 'package'"
return 0
example = CustomerRequest(request="Where is my package?", response="Your P*CKAG* will arrive tomorrow at 10:00 AM.")
def test_agent_behavior():
with pytest.raises(JudgmentTestError):
client.run_evaluation(
examples=[example],
scorers=[ResolutionScorer()],
project_name="default_project",
assert_test=True
)
```
# Third-Party Integrations
URL: /documentation/integrations/introduction
Connect Judgment with popular AI frameworks and observability tools for seamless tracing and monitoring.
***
title: Third-Party Integrations
description: Connect Judgment with popular AI frameworks and observability tools for seamless tracing and monitoring.
---------------------------------------------------------------------------------------------------------------------
**Third-party integrations** extend Judgment's capabilities by automatically capturing traces from popular AI frameworks and observability tools. These integrations eliminate the need for manual instrumentation, providing seamless monitoring of your AI applications.
## How Integrations Work
Integrations automatically capture traces from your existing AI frameworks and send them to Judgment. This requires minimal code changes:
### Initialize the Integration
The top of your file should look like this:
```python
from judgeval.tracer import Tracer
from judgeval.integrations.framework import FrameworkIntegration
tracer = Tracer(project_name="your_project")
FrameworkIntegration.initialize()
```
Always initialize the `Tracer` before calling any integration's `initialize()` method.
## Next Steps
Choose an integration that matches your AI framework:
For multi-agent workflows and graph-based AI applications.
For applications using OpenLit for observability.
# OpenLit Integration
URL: /documentation/integrations/openlit
Export OpenLit traces to the Judgment platform.
***
title: OpenLit Integration
description: Export OpenLit traces to the Judgment platform.
------------------------------------------------------------
**OpenLit integration** sends traces from your OpenLit-instrumented applications to Judgment. If you're already using OpenLit for observability, this integration forwards those traces to Judgment without requiring additional instrumentation.
## Quickstart
### Install Dependencies
```bash
uv add openlit judgeval openai
```
```bash
pip install openlit judgeval openai
```
### Initialize Integration
```python title="setup.py"
from judgeval.tracer import Tracer
from judgeval.integrations.openlit import Openlit
tracer = Tracer(project_name="openlit_project")
Openlit.initialize()
```
Always initialize the `Tracer` before calling `Openlit.initialize()` to ensure proper trace routing.
### Add to Existing Code
Add these lines to your existing OpenLit-instrumented application:
```python
from openai import OpenAI
from judgeval.tracer import Tracer # [!code ++]
from judgeval.integrations.openlit import Openlit # [!code ++]
tracer = Tracer(project_name="openlit-agent") # [!code highlight]
Openlit.initialize() # [!code highlight]
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[{"role": "user", "content": "Hello, world!"}]
)
print(response.choices[0].message.content)
```
All OpenLit traces are exported to the Judgment platform.
**No OpenLit Initialization Required**: When using Judgment's OpenLit integration, you don't need to call `openlit.init()` separately. The `Openlit.initialize()` call handles all necessary OpenLit setup automatically.
```python
import openlit # [!code --]
openlit.init() # [!code --]
from judgeval.tracer import Tracer # [!code ++]
from judgeval.integrations.openlit import Openlit # [!code ++]
tracer = Tracer(project_name="your_project") # [!code ++]
Openlit.initialize() # [!code ++]
from openai import OpenAI
client = OpenAI()
```
## Example: Multi-Workflow Application
**Tracking Non-OpenLit Operations**: Use `@tracer.observe()` to track any function or method that's not automatically captured by OpenLit. The multi-workflow example below shows how `@tracer.observe()` (highlighted) can be used to monitor custom logic and operations that happen outside your OpenLit-instrumented workflows.
```python title="multi_workflow_example.py"
from judgeval.tracer import Tracer
from judgeval.integrations.openlit import Openlit
from openai import OpenAI
tracer = Tracer(project_name="multi_workflow_app")
Openlit.initialize()
client = OpenAI()
def analyze_text(text: str) -> str:
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": f"Analyze: {text}"}
]
)
return response.choices[0].message.content
def summarize_text(text: str) -> str:
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": f"Summarize: {text}"}
]
)
return response.choices[0].message.content
def generate_content(prompt: str) -> str:
response = client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": "You are a creative AI assistant."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
@tracer.observe(span_type="function") # [!code highlight]
def main():
text = "The future of artificial intelligence is bright and full of possibilities."
analysis = analyze_text(text)
summary = summarize_text(text)
story = generate_content(f"Create a story about: {text}")
print(f"Analysis: {analysis}")
print(f"Summary: {summary}")
print(f"Story: {story}")
if __name__ == "__main__":
main()
```
## Next Steps
Trace Langgraph graph executions and workflows.
Monitor your AI applications in production with behavioral scoring.
Learn more about Judgment's tracing capabilities and advanced configuration.
# Agent Behavioral Monitoring
URL: /documentation/performance/agent-behavior-monitoring
Run real-time checks on your agents' behavior in production.
***
title: Agent Behavioral Monitoring
description: Run real-time checks on your agents' behavior in production.
-------------------------------------------------------------------------
**Agent behavioral monitoring** (ABM) lets you run systematic scorer frameworks directly on your live agents in production, alerting engineers the instant agents begin to misbehave so they can push hotfixes before customers are affected.
## Quickstart
Get your agents monitored in production with **server-hosted scorers** - zero latency impact and secure execution.
### Create your Custom Scorer
Build scoring logic to evaluate your agent's behavior. This example monitors a customer service agent to ensure it addresses package inquiries.
We've defined the scoring logic in `customer_service_scorer.py`:
```python title="customer_service_scorer.py"
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
from openai import OpenAI
# Define your data structure
class CustomerRequest(Example):
request: str
response: str
# Create your custom scorer
class PackageInquiryScorer(ExampleScorer):
name: str = "Package Inquiry Scorer"
server_hosted: bool = True # Enable server hosting
async def a_score_example(self, example: CustomerRequest):
client = OpenAI()
# Use LLM to evaluate if response addresses package inquiry
evaluation_prompt = f"""
Evaluate if the customer service response adequately addresses a package inquiry.
Customer request: {example.request}
Agent response: {example.response}
Does the response address package-related concerns? Answer only "YES" or "NO".
"""
completion = client.chat.completions.create(
model="gpt-5-mini",
messages=[{"role": "user", "content": evaluation_prompt}]
)
evaluation = completion.choices[0].message.content.strip().upper()
if evaluation == "YES":
self.reason = "LLM evaluation: Response appropriately addresses package inquiry"
return 1.0
else:
self.reason = "LLM evaluation: Response doesn't adequately address package inquiry"
return 0.0
```
**Server-hosted scorers** run in secure Firecracker microVMs with zero impact on your application latency.
### Upload your Scorer
Deploy your scorer to our secure infrastructure with a single command:
```bash
echo -e "pydantic\nopenai" > requirements.txt
uv run judgeval upload_scorer customer_service_scorer.py requirements.txt
```
```bash
echo -e "pydantic\nopenai" > requirements.txt
judgeval upload_scorer customer_service_scorer.py requirements.txt
```
Your scorer runs in its own secure sandbox. Re-upload anytime your scoring logic changes.
### Monitor your Agent in Production
Instrument your agent with tracing and online evaluation:
**Note:** This example uses OpenAI. Make sure you have `OPENAI_API_KEY` set in your environment variables before running.
```python title="monitored_agent.py"
from judgeval.tracer import Tracer, wrap
from openai import OpenAI
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
from customer_service_scorer import PackageInquiryScorer, CustomerRequest
judgment = Tracer(project_name="customer_service")
client = wrap(OpenAI()) # Auto-tracks all LLM calls
class CustomerServiceAgent:
@judgment.observe(span_type="tool")
def handle_request(self, request: str) -> str:
# Generate response using OpenAI
completion = client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": "You are a helpful customer service agent. Address customer inquiries professionally and helpfully."},
{"role": "user", "content": request}
]
)
response = completion.choices[0].message.content
# Online evaluation with server-hosted scorer
judgment.async_evaluate(
scorer=PackageInquiryScorer(),
example=CustomerRequest(request=request, response=response),
sampling_rate=0.95 # Scores 95% of agent runs
)
return response
@judgment.agent()
@judgment.observe(span_type="function")
def run(self, request: str) -> str:
return self.handle_request(request)
# Example usage
agent = CustomerServiceAgent()
result = agent.run("Where is my package? I ordered it last week.")
print(result)
```
**Key Components:**
* **`wrap(OpenAI())`** automatically tracks all LLM API calls
* **`@judgment.observe()`** captures all agent interactions
* **`judgment.async_evaluate()`** runs hosted scorers with zero latency impact
* **`sampling_rate`** controls behavior scoring frequency (0.95 = 95% of requests)
Scorers can take time to execute, so they may appear slightly delayed on the UI.
You should see the online scoring results attached to the relevant trace span on the Judgment platform:
## Advanced Features
### Multi-Agent System Tracing
When working with multi-agent systems, use the `@judgment.agent()` decorator to track which agent is responsible for each tool call in your trace.
Only decorate the **entry point method** of each agent with `@judgment.agent()` and `@judgment.observe()`. Other methods within the same agent only need `@judgment.observe()`.
Here's a complete multi-agent system example with a flat folder structure:
```python title="main.py"
from planning_agent import PlanningAgent
if __name__ == "__main__":
planning_agent = PlanningAgent("planner-1")
goal = "Build a multi-agent system"
result = planning_agent.plan(goal)
print(result)
```
```python title="utils.py"
from judgeval.tracer import Tracer
judgment = Tracer(project_name="multi-agent-system")
```
```python title="planning_agent.py"
from utils import judgment
from research_agent import ResearchAgent
from task_agent import TaskAgent
class PlanningAgent:
def __init__(self, id):
self.id = id
@judgment.agent() # Only add @judgment.agent() to the entry point function of the agent
@judgment.observe()
def invoke_agent(self, goal):
print(f"Agent {self.id} is planning for goal: {goal}")
research_agent = ResearchAgent("Researcher1")
task_agent = TaskAgent("Tasker1")
research_results = research_agent.invoke_agent(goal)
task_result = task_agent.invoke_agent(research_results)
return f"Results from planning and executing for goal '{goal}': {task_result}"
@judgment.observe() # No need to add @judgment.agent() here
def random_tool(self):
pass
```
```python title="research_agent.py"
from utils import judgment
class ResearchAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, topic):
return f"Research notes for topic: {topic}: Findings and insights include..."
```
```python title="task_agent.py"
from utils import judgment
class TaskAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, task):
result = f"Performed task: {task}, here are the results: Results include..."
return result
```
The trace will show up in the Judgment platform clearly indicating which agent called which method:
Each agent's tool calls are clearly associated with their respective classes, making it easy to follow the execution flow across your multi-agent system.
### Toggling Monitoring
If your setup requires you to toggle monitoring intermittently, you can disable monitoring by:
* Setting the `JUDGMENT_MONITORING` environment variable to `false` (Disables tracing)
```bash
export JUDGMENT_MONITORING=false
```
* Setting the `JUDGMENT_EVALUATIONS` environment variable to `false` (Disables scoring on traces)
```bash
export JUDGMENT_EVALUATIONS=false
```
## Next steps
Take action on your agent failures by configuring alerts triggered on your agents' behavior in production.
# Alerts
URL: /documentation/performance/alerts
Set up rules to automatically notify you or perform actions when your agent misbehaves in production.
***
title: 'Alerts'
description: 'Set up rules to automatically notify you or perform actions when your agent misbehaves in production.'
--------------------------------------------------------------------------------------------------------------------
Rules allow you to define specific conditions for the evaluation metrics output by scorers running in your production environment. When met, these rules can trigger notifications and actions. They serve as the foundation for the alerting system and help you monitor your agent's performance.
## Overview
A rule consists of one or more [conditions](#filter-conditions), each tied to a specific metric that is supported by our built-in scorers (like Faithfulness or Answer Relevancy), a custom-made [Prompt Scorer](/documentation/evaluation/prompt-scorers) or [Trace Prompt Scorer](/documentation/evaluation/prompt-scorers#trace-prompt-scorers), a [server-hosted Custom Scorer](/documentation/performance/online-evals), or a simple static metric (trace duration or LLM cost).
When evaluations are performed, the rules engine checks if the measured scores satisfy the conditions set in your rules, triggering an alert in the event that they do. Based on the rule's configuration, an alert can lead to [notifications being sent or actions being executed](/documentation/performance/alerts#actions-and-notifications) through various channels.
Optionally, rules can be configured such that a single alert does not immediately trigger a notification or action. Instead, you can require the rule to generate a [minimum number of alerts within a specified time window](/documentation/performance/alerts#alert-frequency) before any notification/action is sent. You can also enforce a [cooldown period](/documentation/performance/alerts#action-cooldown-period) to ensure a minimum time elapses between consecutive notifications/actions.
Rules and actions do not support local Custom Scorers. As highlighted in [Online Behavioral Monitoring](/documentation/performance/online-evals), your Custom Scorers must be uploaded to our infrastructure before they can be used in a rule
Rules are created through the monitoring section of your project. To create a new rule:
1. Navigate to the Monitoring section in your project dashboard
2. Click "Create New Rule" or access the rules configuration
3. Configure the rule settings as described below
## Rule Configuration
### Basic Information
* **Rule Name**: A descriptive name for your rule (required)
* **Description**: Optional description explaining the rule's purpose
### Filter Conditions
The filter section allows you to define when the rule should trigger. You can:
* **Match Type**: Choose between "AND" (all conditions must be met) or "OR" (any condition can trigger the rule)
* **Conditions**: Add one or more conditions, each specifying:
* **Metric**: Select from available built-in scorers (e.g., Faithfulness, Answer Relevancy), Prompt Scorers/Trace Prompt Scorers, hosted Custom Scorers, or static metrics (e.g. trace duration, trace LLM cost)
* **Operator**: Choose a comparison operator (`>=`, `<=`, `==`, `<`, `>`) *or* a success condition (`succeeds`, `fails`)
* **Value**: Set the threshold value (only available for comparison operators)
Success condition operators (`succeeds`, `fails`) are only available for non-static metrics (built-in, prompt, and custom scorers). Success is evaluated against the thresholds you configured when creating or instantiating your scorers.
You can add multiple conditions by clicking "Add condition" to create complex rules.
The metric dropdown includes various built-in scorers you can choose from:
## Alert Frequency
Configure the minimum number of alerts the rule must trigger within a certain time window before an action is taken or a notification is sent:
By default, this is set to `1` time in `1 second`, which means every alert triggered by the rule will invoke a notification/action.
## Action Cooldown Period
Configure the minimum amount of time that must elapse after the last invocation of a notification/action before another invocation can occur:
By default, this is set to `0 seconds`, which means there is no cooldown and actions/notifications can be invoked as often as necessary.
## Actions and Notifications
Configure what happens when the rule conditions have triggered a number of alerts satisfying the `Alert Frequency` parameter *and* the `Action Cooldown Period` has expired:
### Add to Dataset
* Automatically add traces with failing evaluations to a dataset for further analysis
* Select your target dataset from the dropdown menu
### Email Notifications
* Send notifications to one or more specified email addresses
### Slack Integration
* Post alerts to Slack channels through app integration
* Connect Judgment to your Slack workspace through the App Integrations section in `Settings` → `Notifications`
* Once connected, you can select which channels to send notifications to for the current rule
When configuring Slack in your rule actions, you'll see the connection status:
### PagerDuty Integration
* Create incidents on PagerDuty for critical issues
* Configure integration keys
* Set incident severity levels
## Managing Rules
Once created, rules can be managed through the rules dashboard:
* **Add Rules**: Add new rules
* **Edit Rules**: Modify existing rule conditions and actions
* **Delete Rules**: Remove rules that are no longer needed
# Tracing
URL: /documentation/performance/tracing
Track agent behavior and evaluate performance in real-time with OpenTelemetry-based tracing.
***
title: Tracing
description: Track agent behavior and evaluate performance in real-time with OpenTelemetry-based tracing.
---------------------------------------------------------------------------------------------------------
**Tracing** provides comprehensive observability for your AI agents, automatically capturing execution traces, spans, and performance metrics. All tracing is built on **OpenTelemetry** standards, so you can monitor agent behavior **regardless of implementation language**.
## Quickstart
### Initialize the Tracer
Set up your tracer with your project configuration:
```python title="agent.py"
from judgeval.tracer import Tracer, wrap
from openai import OpenAI
# Initialize tracer (singleton pattern - only one instance per agent, even for multi-file agents)
judgment = Tracer(project_name="default_project")
# Auto-trace LLM calls - supports OpenAI, Anthropic, Together, Google GenAI, and Groq
client = wrap(OpenAI())
```
**Supported LLM Providers:** OpenAI, Anthropic, Together, Google GenAI, and Groq. The `wrap()` function automatically tracks all API calls including streaming responses for both sync and async clients.
Set your API credentials using environment variables: `JUDGMENT_API_KEY` and `JUDGMENT_ORG_ID`
Make sure your `OPENAI_API_KEY` (or equivalent for other providers) is also set in your environment.
### Instrument Your Agent
Add tracing decorators to capture agent behavior:
```python title="agent.py"
class QAAgent:
def __init__(self, client):
self.client = client
@judgment.observe(span_type="tool")
def process_query(self, query):
response = self.client.chat.completions.create(
model="gpt-5-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": f"I have a query: {query}"}
]
) # Automatically traced
return f"Response: {response.choices[0].message.content}"
@judgment.agent()
@judgment.observe(span_type="function")
def invoke_agent(self, query):
result = self.process_query(query)
return result
if __name__ == "__main__":
agent = QAAgent(client)
print(agent.invoke_agent("What is the capital of the United States?"))
```
**Key Components:**
* **`@judgment.observe()`** captures tool interactions, inputs, outputs, and execution time
* **`wrap()`** automatically tracks all LLM API calls including token usage and costs
* **`@judgment.agent()`** identifies which agent is responsible for each tool call in multi-agent systems
All traced data flows to the Judgment platform in real-time with zero latency impact on your application.
### View Traces in the Platform
## What Gets Captured
The Tracer automatically captures comprehensive execution data:
* **Execution Flow:** Function call hierarchy, execution duration, and parent-child span relationships
* **LLM Interactions:** Model parameters, prompts, responses, token usage, and cost per API call
* **Agent Behavior:** Tool usage, function inputs/outputs, state changes, and error states
* **Performance Metrics:** Latency per span, total execution time, and cost tracking
## OpenTelemetry Integration
Judgment's tracing is built on OpenTelemetry, the industry-standard observability framework. This means:
**Standards Compliance:**
* Compatible with existing OpenTelemetry tooling
* Follows OTEL semantic conventions
* Integrates with OTEL collectors and exporters
**Advanced Configuration:**
You can integrate Judgment's tracer with your existing OpenTelemetry setup:
```python title="otel_integration.py"
from judgeval.tracer import Tracer
from opentelemetry.sdk.trace import TracerProvider
tracer_provider = TracerProvider()
# Initialize with OpenTelemetry resource attributes
judgment = Tracer(
project_name="default_project",
resource_attributes={
"service.name": "my-ai-agent",
"service.version": "1.2.0",
"deployment.environment": "production"
}
)
# Connect to your existing OTEL infrastructure
tracer_provider.add_span_processor(judgment.get_processor())
tracer = tracer_provider.get_tracer(__name__)
# Use native OTEL spans alongside Judgment decorators
def process_request(question: str) -> str:
with tracer.start_as_current_span("process_request_span") as span:
span.set_attribute("input", question)
answer = answer_question(question)
span.set_attribute("output", answer)
return answer
```
**Resource Attributes:**
Resource attributes describe the entity producing telemetry data. Common attributes include:
* `service.name` - Name of your service
* `service.version` - Version number
* `deployment.environment` - Environment (production, staging, etc.)
* `service.namespace` - Logical grouping
See the [OpenTelemetry Resource specification](https://opentelemetry.io/docs/specs/otel/configuration/sdk-environment-variables/) for standard attributes.
## Multi-Agent System Tracing
Track which agent is responsible for each tool call in complex multi-agent systems.
Only decorate the **entry point method** of each agent with `@judgment.agent()` and `@judgment.observe()`. Other methods within the same agent only need `@judgment.observe()`.
### Example Multi-Agent System
```python title="main.py"
from planning_agent import PlanningAgent
if __name__ == "__main__":
planning_agent = PlanningAgent("planner-1")
goal = "Build a multi-agent system"
result = planning_agent.invoke_agent(goal)
print(result)
```
```python title="utils.py"
from judgeval.tracer import Tracer
judgment = Tracer(project_name="multi-agent-system")
```
```python title="planning_agent.py"
from utils import judgment
from research_agent import ResearchAgent
from task_agent import TaskAgent
class PlanningAgent:
def __init__(self, id):
self.id = id
@judgment.agent() # Only on entry point
@judgment.observe()
def invoke_agent(self, goal):
print(f"Agent {self.id} is planning for goal: {goal}")
research_agent = ResearchAgent("Researcher1")
task_agent = TaskAgent("Tasker1")
research_results = research_agent.invoke_agent(goal)
task_result = task_agent.invoke_agent(research_results)
return f"Results from planning and executing for goal '{goal}': {task_result}"
@judgment.observe() # No @judgment.agent() needed
def random_tool(self):
pass
```
```python title="research_agent.py"
from utils import judgment
class ResearchAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, topic):
return f"Research notes for topic: {topic}: Findings and insights include..."
```
```python title="task_agent.py"
from utils import judgment
class TaskAgent:
def __init__(self, id):
self.id = id
@judgment.agent()
@judgment.observe()
def invoke_agent(self, task):
result = f"Performed task: {task}, here are the results: Results include..."
return result
```
The trace clearly shows which agent called which method:
## Distributed Tracing
Distributed tracing allows you to track requests across multiple services and systems, providing end-to-end visibility into complex workflows. This is essential for understanding how your AI agents interact with external services and how data flows through your distributed architecture.
**Important Configuration Notes:**
* **Project Name**: Use the same `project_name` across all services so traces appear in the same project in the Judgment platform
* **Service Name**: Set distinct `service.name` in resource attributes to differentiate between services in your distributed system
### Sending Trace State
When your agent needs to propagate trace context to downstream services, you can manually extract and send trace context.
**Dependencies:**
```bash
uv add judgeval requests
```
```python title="agent.py"
from judgeval.tracer import Tracer
from opentelemetry.propagate import inject
import requests
judgment = Tracer(
project_name="distributed-system",
resource_attributes={"service.name": "agent-client"},
)
@judgment.observe(span_type="function")
def call_external_service(data):
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ...",
}
inject(headers)
response = requests.post(
"http://localhost:8001/process",
json=data,
headers=headers
)
return response.json()
if __name__ == "__main__":
result = call_external_service({"query": "Hello from client"})
print(result)
```
**Dependencies:**
```bash
npm install judgeval @opentelemetry/api
```
```typescript title="agent.ts"
import { context, propagation } from "@opentelemetry/api";
import { NodeTracer, TracerConfiguration } from "judgeval";
const config = TracerConfiguration.builder()
.projectName("distributed-system")
.resourceAttributes({ "service.name": "agent-client" })
.build();
const judgment = await NodeTracer.createWithConfiguration(config);
async function makeRequest(url: string, options: RequestInit = {}): Promise {
const headers = {};
propagation.inject(context.active(), headers);
const response = await fetch(url, {
...options,
headers: { "Content-Type": "application/json", ...headers },
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
async function callExternalService(data: any) {
const callExternal = judgment.observe(async function callExternal(data: any) {
return await makeRequest("http://localhost:8001/process", {
method: "POST",
body: JSON.stringify(data),
});
}, "span");
return callExternal(data);
}
const result = await callExternalService({ message: "Hello!" });
console.log(result);
```
### Receiving Trace State
When your service receives requests from other services, you can use middleware to automatically extract and set the trace context for all incoming requests.
**Dependencies:**
```bash
uv add judgeval fastapi uvicorn
```
```python title="service.py"
from judgeval.tracer import Tracer
from opentelemetry.propagate import extract
from opentelemetry import context as otel_context
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
from fastapi import FastAPI, Request
judgment = Tracer(
project_name="distributed-system",
resource_attributes={"service.name": "agent-server"},
)
app = FastAPI()
FastAPIInstrumentor.instrument_app(app)
@app.middleware("http")
async def trace_context_middleware(request: Request, call_next):
ctx = extract(dict(request.headers))
token = otel_context.attach(ctx)
try:
response = await call_next(request)
return response
finally:
otel_context.detach(token)
@judgment.observe(span_type="function")
def process_request(data):
return {"message": "Hello from Python server!", "received_data": data}
@app.post("/process")
async def handle_process(request: Request):
result = process_request(await request.json())
return result
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8001)
```
**Dependencies:**
```bash
npm install judgeval @opentelemetry/api express
```
```typescript title="service.ts"
import express from "express";
import { NodeTracer, TracerConfiguration } from "judgeval";
import { context, propagation } from "@opentelemetry/api";
const config = TracerConfiguration.builder()
.projectName("distributed-system")
.resourceAttributes({ "service.name": "agent-server" })
.build();
const judgment = await NodeTracer.createWithConfiguration(config);
const app = express();
app.use(express.json());
app.use((req, res, next) => {
const parentContext = propagation.extract(context.active(), req.headers);
context.with(parentContext, () => {
next();
});
});
async function processRequest(data: any) {
const process = judgment.observe(async function processRequest(data: any) {
return { message: "Hello from server!", received_data: data };
}, "span");
return process(data);
}
app.post("/process", async (req, res) => {
const result = await processRequest(req.body);
res.json(result);
});
app.listen(8001, () => console.log("Server running on port 8001"));
```
**Testing Distributed Tracing:**
1. **Start the server** (Python FastAPI or TypeScript Express) on port 8001
2. **Run the client** (Python or TypeScript) to send requests to the server
3. **View traces** in the Judgment platform to see the distributed trace flow
The client examples will automatically send trace context to the server, creating a complete distributed trace across both services.
## Toggling Monitoring
If your setup requires you to toggle monitoring intermittently, you can disable monitoring by:
* Setting the `JUDGMENT_MONITORING` environment variable to `false` (Disables tracing)
```bash
export JUDGMENT_MONITORING=false
```
* Setting the `JUDGMENT_EVALUATIONS` environment variable to `false` (Disables scoring on traces)
```bash
export JUDGMENT_EVALUATIONS=false
```
## Next Steps
Explore the complete Tracer API including span access, metadata, and advanced configuration.
Configure alerts triggered on agent behavior to catch issues before they impact users.
Run real-time behavioral monitoring on your production agents with server-hosted scorers.
# Configuration Types
URL: /sdk-reference/data-types/config-types
Configuration objects and interfaces used to set up SDK components
***
title: Configuration Types
description: Configuration objects and interfaces used to set up SDK components
-------------------------------------------------------------------------------
## Overview
Configuration types define how different components of the JudgmentEval SDK should behave. These types are used to customize scoring behavior, API clients, and evaluation parameters.
## Internal Configuration Types
For reference only - users should create scorers via [`ExampleScorer`](/sdk-reference/data-types/core-types#examplescorer) instead of implementing [`BaseScorer`](/sdk-reference/data-types/config-types#basescorer) or [`APIScorerConfig`](/sdk-reference/data-types/config-types#apiscorerconfig) directly
### `BaseScorer`
Abstract base class for implementing custom scoring logic.
#### `score(input: str, output: str, expected: str = None) -> float` \[!toc]
Main evaluation method that must be implemented by subclasses. Returns a numeric score for the given input/output pair.
```py
def score(self, input: str, output: str, expected: str = None) -> float:
# Custom scoring logic here
return 0.85
```
#### `get_name() -> str` \[!toc]
Returns the name/identifier for this scorer. Override to customize.
```python
# BaseScorer is the abstract base class - for reference only
# In practice, create scorers using ExampleScorer:
from judgeval import ExampleScorer
# Create a custom scorer using ExampleScorer (recommended approach)
custom_scorer = ExampleScorer(
name="similarity_scorer",
scorer_fn=lambda input, output, expected: 1.0 if expected and expected.lower() in output.lower() else 0.0
)
# Use the scorer
result = custom_scorer.score(
input="What is 2+2?",
output="The answer is 4",
expected="4"
)
```
### `APIScorerConfig`
Configuration object for built-in Judgment scorers.
#### `name` \[!toc]
Unique identifier for the scorer configuration
```py
"accuracy_scorer"
```
#### `prompt` \[!toc]
The evaluation prompt that will be used to judge responses
```py
"Rate the accuracy of this answer on a scale of 1-5, where 5 is completely accurate."
```
#### `options` \[!toc]
Additional configuration options for the scorer
```py
{
"model": "gpt-4",
"temperature": 0.0,
"max_tokens": 100
}
```
#### `judgment_api_key` \[!toc]
API key for Judgment platform authentication. Defaults to `JUDGMENT_API_KEY` environment variable
#### `organization_id` \[!toc]
Organization identifier for API requests. Defaults to `JUDGMENT_ORG_ID` environment variable
## Utility Types
### Common Configuration Patterns
#### `ScorerType`
Commonly used union type accepting either API configuration or custom scorer instances
#### `ConfigDict`
General-purpose configuration dictionary for flexible parameter passing
#### `OptionalConfig`
Optional configuration dictionary, commonly used for metadata and additional options
#### `FileFormat`
Supported file formats for dataset import/export operations
```py
# Used in dataset export methods
dataset.save(
file_type="json", # or "yaml"
dir_path="/path/to/save"
)
```
# Core Data Types
URL: /sdk-reference/data-types/core-types
Essential data types used throughout the JudgmentEval SDK
***
title: Core Data Types
description: Essential data types used throughout the JudgmentEval SDK
----------------------------------------------------------------------
## Overview
Core data types represent the fundamental objects you'll work with when using the JudgmentEval SDK. These types are used across multiple SDK components for evaluation, tracing, and dataset management.
## `Example`
Represents a single evaluation example containing input data and expected outputs for testing AI systems.
#### `input` \[!toc]
The input prompt or query to be evaluated
```py
"What is the capital of France?"
```
#### `expected_output` \[!toc]
The expected or ideal response for comparison during evaluation
```py
"The capital of France is Paris."
```
#### `actual_output` \[!toc]
The actual response generated by the system being evaluated
```py
"Paris is the capital city of France."
```
#### `retrieval_context` \[!toc]
Additional context retrieved from external sources (e.g., RAG systems)
```py
"According to Wikipedia: Paris is the capital and most populous city of France..."
```
#### `additional_metadata` \[!toc]
Extended metadata for storing custom fields and evaluation-specific information
```py
{
"model_version": "gpt-4-0125",
"temperature": 0.7,
"response_time_ms": 1250
}
```
#### `metadata` \[!toc]
Additional context or information about the example
```py
{
"category": "geography",
"difficulty": "easy",
"source": "world_facts_dataset"
}
```
```python
from judgeval.data import Example
# Basic example
example = Example(
input="What is 2 + 2?",
expected_output="4"
)
# Example with evaluation results
evaluated_example = Example(
input="What is the capital of France?",
expected_output="Paris",
actual_output="Paris is the capital city of France.",
metadata={
"category": "geography",
"difficulty": "easy"
}
)
# RAG example with retrieval context
rag_example = Example(
input="Explain quantum computing",
expected_output="Quantum computing uses quantum mechanical phenomena...",
actual_output="Quantum computing is a revolutionary technology...",
retrieval_context="According to research papers: Quantum computing leverages quantum mechanics...",
additional_metadata={
"model_version": "gpt-4-0125",
"temperature": 0.7,
"retrieval_score": 0.95
}
)
```
## `ExampleScorer`
A custom scorer class that extends BaseScorer for creating specialized evaluation logic for individual examples.
#### `score_type` \[!toc]
Type identifier for the scorer, defaults to "Custom"
```py
"Custom"
```
#### `required_params` \[!toc]
List of required parameters for the scorer
```py
["temperature", "model_version"]
```
#### `a_score_example` \[!toc]
Asynchronously measures the score on a single example. Must be implemented by subclasses.
```py
async def a_score_example(self, example: Example, *args, **kwargs) -> float:
# Custom scoring logic here
return score
```
```python
from judgeval import JudgmentClient
from judgeval.data import Example
from judgeval.scorers.example_scorer import ExampleScorer
client = JudgmentClient()
class CorrectnessScorer(ExampleScorer):
score_type: str = "Correctness"
async def a_score_example(self, example: Example) -> float:
# Replace this logic with your own scoring logic
if "Washington, D.C." in example.actual_output:
self.reason = "The answer is correct because it contains 'Washington, D.C.'."
return 1.0
self.reason = "The answer is incorrect because it does not contain 'Washington, D.C.'."
return 0.0
example = Example(
input="What is the capital of the United States?",
expected_output="Washington, D.C.",
actual_output="The capital of the U.S. is Washington, D.C."
)
client.run_evaluation(
examples=[example],
scorers=[CorrectnessScorer()],
project_name="default_project",
)
```
# Data Types Reference
URL: /sdk-reference/data-types
Complete reference for all data types used in the JudgmentEval SDK
***
title: Data Types Reference
description: Complete reference for all data types used in the JudgmentEval SDK
-------------------------------------------------------------------------------
## Overview
The JudgmentEval SDK uses a well-defined set of data types to ensure consistency across all components. This section provides comprehensive documentation for all types you'll encounter when working with evaluations, datasets, tracing, and scoring.
## Quick Reference
| Type Category | Key Types | Primary Use Cases |
| ----------------------------------------------------------------- | -------------------------------------- | ------------------------------------------ |
| [**Core Types**](/sdk-reference/data-types/core-types) | `Example`, `Trace`, `ExampleScorer` | Dataset creation, evaluation runs, tracing |
| [**Configuration Types**](/sdk-reference/data-types/config-types) | `APIScorerConfig`, `BaseScorer` | Setting up scorers and SDK components |
| [**Response Types**](/sdk-reference/data-types/response-types) | `EvaluationResult`, `JudgmentAPIError` | Handling results and errors |
## Type Categories
### Core Data Types
Essential objects that represent the fundamental concepts in JudgmentEval:
* **[Example](/sdk-reference/data-types/core-types#example)** - Input/output pairs for evaluation
* **[Trace](/sdk-reference/data-types/core-types#trace)** - Execution traces from AI agent runs
* **[ExampleScorer](/sdk-reference/data-types/core-types#examplescorer)** - Pairing of examples with scoring methods
### Configuration Types
Objects used to configure SDK behavior and customize evaluation:
* **[APIScorerConfig](/sdk-reference/data-types/config-types#apiscorerconfig)** - Configuration for API-based scorers
* **[BaseScorer](/sdk-reference/data-types/config-types#basescorer)** - Base class for custom scoring logic
* **[Utility Types](/sdk-reference/data-types/config-types#utility-types)** - Common configuration patterns
### Response & Exception Types
Types returned by SDK methods and exceptions that may be raised:
* **[JudgmentAPIError](/sdk-reference/data-types/response-types#judgmentapierror)** - Primary SDK exception type
* **[EvaluationResult](/sdk-reference/data-types/response-types#evaluationresult)** - Results from evaluation runs
* **[DatasetInfo](/sdk-reference/data-types/response-types#datasetinfo)** - Dataset operation results
## Common Usage Patterns
### Creating Examples
```python
from judgeval import Example
# Basic example
example = Example(
input="What is the capital of France?",
expected_output="Paris"
)
# With metadata
example_with_context = Example(
input="Explain machine learning",
expected_output="Machine learning is...",
metadata={"topic": "AI", "difficulty": "intermediate"}
)
```
### Configuring Scorers
```python
from judgeval.scorers import APIScorerConfig, PromptScorer
# API-based scorer
api_config = APIScorerConfig(
name="accuracy_checker",
prompt="Rate accuracy from 1-5"
)
# Custom scorer instance
custom_scorer = PromptScorer(
name="custom_evaluator",
prompt="Evaluate response quality..."
)
```
### Handling Results
```python
from judgeval import JudgmentClient, JudgmentAPIError
try:
result = client.evaluate(examples=[...], scorers=[...])
print(f"Average score: {result.aggregate_scores['mean']}")
for example_result in result.results:
print(f"Score: {example_result.score}")
except JudgmentAPIError as e:
print(f"Evaluation failed: {e.message}")
```
## Type Import Reference
Most types can be imported directly from the main package:
```python
# Core types
from judgeval import Example, ExampleScorer
# Scorer configurations
from judgeval.scorers import APIScorerConfig, BaseScorer, PromptScorer
# Client and exceptions
from judgeval import JudgmentClient, JudgmentAPIError
# Dataset operations
from judgeval import Dataset
```
## Next Steps
* Explore [Core Types](/sdk-reference/data-types/core-types) to understand fundamental SDK objects
* Review [Configuration Types](/sdk-reference/data-types/config-types) for customizing SDK behavior
* Check [Response Types](/sdk-reference/data-types/response-types) for proper error handling
For practical examples, see the individual SDK component documentation:
* [Tracer](/sdk-reference/tracing) - For tracing and observability
* [Dataset](/sdk-reference/dataset) - For dataset management
* [JudgmentClient](/sdk-reference/judgment-client) - For evaluation operations
# Response & Exception Types
URL: /sdk-reference/data-types/response-types
Return types and exceptions used throughout the JudgmentEval SDK
***
title: Response & Exception Types
description: Return types and exceptions used throughout the JudgmentEval SDK
-----------------------------------------------------------------------------
## Overview
Response and exception types define the structure of data returned by SDK methods and the errors that may occur during operation. Understanding these types helps with proper error handling and result processing.
## Evaluation Result Types
### `ScoringResult`
Contains the output of one or more scorers applied to a single example. Represents the complete evaluation results for one input with its actual output, expected output, and all applied scorer results.
#### `success` \[!toc]
Whether the evaluation was successful. True when all scorers applied to this example returned a success.
#### `scorers_data` \[!toc]
List of individual scorer results for this evaluation
#### `data_object` \[!toc]
The original example object that was evaluated
#### `name` \[!toc]
Optional name identifier for this scoring result
#### `trace_id` \[!toc]
Unique identifier linking this result to trace data
#### `run_duration` \[!toc]
Time taken to complete the evaluation in seconds
#### `evaluation_cost` \[!toc]
Estimated cost of running the evaluation (e.g., API costs)
```python
from judgeval import JudgmentClient
client = JudgmentClient()
results = client.evaluate(examples=[...], scorers=[...])
for result in results:
if result.success:
print(f"Evaluation succeeded in {result.run_duration:.2f}s")
for scorer_data in result.scorers_data:
print(f" {scorer_data.name}: {scorer_data.score}")
else:
print("Evaluation failed")
```
### `ScorerData`
Individual scorer result containing the score, reasoning, and metadata for a single scorer applied to an example.
#### `name` \[!toc]
Name of the scorer that generated this result
#### `threshold` \[!toc]
Threshold value used to determine pass/fail for this scorer
#### `success` \[!toc]
Whether this individual scorer succeeded (score >= threshold)
#### `score` \[!toc]
Numerical score returned by the scorer (typically 0.0-1.0)
#### `reason` \[!toc]
Human-readable explanation of why the scorer gave this result
#### `id` \[!toc]
Unique identifier for this scorer instance
#### `strict_mode` \[!toc]
Whether the scorer was run in strict mode
#### `evaluation_model` \[!toc]
Model(s) used for evaluation (e.g., "gpt-4", \["gpt-4", "claude-3"])
#### `error` \[!toc]
Error message if the scorer failed to execute
#### `additional_metadata` \[!toc]
Extra information specific to this scorer or evaluation run
```python
# Access scorer data from a ScoringResult
scoring_result = client.evaluate(examples=[example], scorers=[faithfulness_scorer])[0]
for scorer_data in scoring_result.scorers_data:
print(f"Scorer: {scorer_data.name}")
print(f"Score: {scorer_data.score} (threshold: {scorer_data.threshold})")
print(f"Success: {scorer_data.success}")
print(f"Reason: {scorer_data.reason}")
if scorer_data.error:
print(f"Error: {scorer_data.error}")
```
## Dataset Operation Types
### `DatasetInfo`
Information about a dataset after creation or retrieval operations.
#### `dataset_id` \[!toc]
Unique identifier for the dataset
#### `name` \[!toc]
Human-readable name of the dataset
#### `example_count` \[!toc]
Number of examples in the dataset
#### `created_at` \[!toc]
When the dataset was created
#### `updated_at` \[!toc]
When the dataset was last modified
## Exception Types
### `JudgmentAPIError`
Primary exception raised when API operations fail due to network, authentication, or server issues.
#### `message` \[!toc]
Human-readable error description
#### `status_code` \[!toc]
HTTP status code from the failed API request
#### `response_data` \[!toc]
Additional details from the API response, if available
* **Authentication failures** (401): Invalid API key or organization ID
* **Rate limiting** (429): Too many requests in a short time period
* **Server errors** (500+): Temporary issues with the Judgment platform
* **Bad requests** (400): Invalid parameters or malformed data
```python
from judgeval import JudgmentClient, JudgmentAPIError
client = JudgmentClient()
try:
result = client.evaluate(examples=[...], scorers=[...])
except JudgmentAPIError as e:
print(f"API Error: {e.message}")
if e.status_code == 401:
print("Check your API key and organization ID")
elif e.status_code == 429:
print("Rate limited - try again later")
else:
print(f"Server error (status {e.status_code})")
```
### Recommended Error Handling
```python
try:
# SDK operations
result = client.evaluate([...])
except JudgmentAPIError as api_error:
# Handle API-specific errors
logger.error(f"API error: {api_error.message}")
if api_error.status_code >= 500:
# Retry logic for server errors
pass
except ConnectionError:
# Handle network issues
logger.error("Network connection failed")
except Exception as e:
# Handle unexpected errors
logger.error(f"Unexpected error: {e}")
```
## Class Instance Types
Some SDK methods return class instances that also serve as API clients:
### `Dataset`
Class instances returned by `Dataset.create()` and `Dataset.get()` that provide both data access and additional methods for dataset management.
```python
# Static methods return Dataset instances
dataset = Dataset.create(name="my_dataset", project_name="default_project")
retrieved_dataset = Dataset.get(name="my_dataset", project_name="default_project")
# Both return Dataset instances with properties and methods
print(dataset.name) # Access properties
dataset.add_examples([...]) # Call instance methods
```
See [Dataset](/sdk-reference/dataset) for complete API documentation including:
* Static methods (`Dataset.create()`, `Dataset.get()`)
* Instance methods (`.add_examples()`, `.add_traces()`, etc.)
* Instance properties (`.name`, `.examples`, `.traces`, etc.)
### `PromptScorer`
Class instances returned by `PromptScorer.create()` and `PromptScorer.get()` that provide scorer configuration and management methods.
```python
# Static methods return PromptScorer instances
scorer = PromptScorer.create(
name="positivity_scorer",
prompt="Is the response positive? Response: {{actual_output}}",
options={"positive": 1, "negative": 0}
)
retrieved_scorer = PromptScorer.get(name="positivity_scorer")
# Both return PromptScorer instances with configuration methods
print(scorer.get_name()) # Access properties
scorer.set_threshold(0.8) # Update configuration
scorer.append_to_prompt("Consider tone and sentiment.") # Modify prompt
```
See [PromptScorer](/sdk-reference/prompt-scorer) for complete API documentation including:
* Static methods (`PromptScorer.create()`, `PromptScorer.get()`)
* Configuration methods (`.set_prompt()`, `.set_options()`, `.set_threshold()`)
* Getter methods (`.get_prompt()`, `.get_options()`, `.get_config()`)
# Langgraph Integration
URL: /documentation/integrations/agent-frameworks/langgraph
Automatically trace Langgraph graph executions and node interactions.
***
title: Langgraph Integration
description: Automatically trace Langgraph graph executions and node interactions.
----------------------------------------------------------------------------------
**Langgraph integration** captures traces from your Langgraph applications, including graph execution flow, individual node calls, and state transitions between nodes.
## Quickstart
### Install Dependencies
```bash
uv add langgraph judgeval langchain-openai
```
```bash
pip install langgraph judgeval langchain-openai
```
### Initialize Integration
```python title="setup.py"
from judgeval.tracer import Tracer
from judgeval.integrations.langgraph import Langgraph
tracer = Tracer(project_name="langgraph_project")
Langgraph.initialize()
```
Always initialize the `Tracer` before calling `Langgraph.initialize()` to ensure proper trace routing.
### Add to Existing Code
Add these lines to your existing Langgraph application:
```python
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from typing import TypedDict, List
from judgeval.tracer import Tracer # [!code ++]
from judgeval.integrations.langgraph import Langgraph # [!code ++]
tracer = Tracer(project_name="langgraph-agent") # [!code highlight]
Langgraph.initialize() # [!code highlight]
class AgentState(TypedDict):
messages: List[dict]
task: str
result: str
def research_agent(state: AgentState) -> AgentState:
llm = ChatOpenAI(model="gpt-5-mini")
response = llm.invoke([HumanMessage(content=f"Research: {state['task']}")])
return {
**state,
"messages": state["messages"] + [{"role": "assistant", "content": response.content}],
"result": f"Research completed for: {state['task']}"
}
graph = StateGraph(AgentState)
graph.add_edge(START, "research")
graph.add_node("research", research_agent)
graph.add_edge("research", END)
workflow = graph.compile()
result = workflow.invoke({
"messages": [],
"task": "Build a web scraper",
"result": ""
})
print(result)
```
All graph executions and node calls are automatically traced.
## Example: Multi-Agent Workflow
```python title="multi_agent_example.py"
from judgeval.tracer import Tracer
from judgeval.integrations.langgraph import Langgraph
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from typing import TypedDict, List
tracer = Tracer(project_name="multi_agent_workflow")
Langgraph.initialize()
class AgentState(TypedDict):
messages: List[dict]
task: str
result: str
def research_agent(state: AgentState) -> AgentState:
llm = ChatOpenAI(model="gpt-5-mini")
response = llm.invoke([HumanMessage(content=f"Research: {state['task']}")])
return {
**state,
"messages": state["messages"] + [{"role": "assistant", "content": response.content}],
"result": f"Research completed for: {state['task']}"
}
def planning_agent(state: AgentState) -> AgentState:
llm = ChatOpenAI(model="gpt-5-mini")
response = llm.invoke([HumanMessage(content=f"Create plan for: {state['task']}")])
return {
**state,
"messages": state["messages"] + [{"role": "assistant", "content": response.content}],
"result": f"Plan created for: {state['task']}"
}
def execution_agent(state: AgentState) -> AgentState:
llm = ChatOpenAI(model="gpt-5-mini")
response = llm.invoke([HumanMessage(content=f"Execute: {state['task']}")])
return {
**state,
"messages": state["messages"] + [{"role": "assistant", "content": response.content}],
"result": f"Task completed: {state['task']}"
}
@tracer.observe(span_type="function") # [!code highlight]
def main():
graph = StateGraph(AgentState)
graph.add_node("research", research_agent)
graph.add_node("planning", planning_agent)
graph.add_node("execution", execution_agent)
graph.set_entry_point("research")
graph.add_edge("research", "planning")
graph.add_edge("planning", "execution")
graph.add_edge("execution", END)
workflow = graph.compile()
result = workflow.invoke({
"messages": [],
"task": "Build a customer service bot",
"result": ""
})
print(result)
if __name__ == "__main__":
main()
```
**Tracking Non-Langgraph Nodes**: Use `@tracer.observe()` to track any function or method that's not part of your Langgraph workflow. This is especially useful for monitoring utility functions, API calls, or other operations that happen outside the graph execution but are part of your overall application flow.
```python title="complete_example.py"
from langgraph.graph import StateGraph, START, END
from judgeval.tracer import Tracer
tracer = Tracer(project_name="my_agent")
@tracer.observe(span_type="function")
def helper_function(data: str) -> str:
# Helper function tracked with @tracer.observe()
return f"Processed: {data}"
def langgraph_node(state):
# Langgraph nodes are automatically traced
# Can call helper functions within nodes
result = helper_function(state["input"])
return {"result": result}
# Set up and invoke Langgraph workflow
graph = StateGraph(dict)
graph.add_node("process", langgraph_node)
graph.add_edge(START, "process")
graph.add_edge("process", END)
workflow = graph.compile()
# Execute the workflow - both Langgraph and helper functions are traced
result = workflow.invoke({"input": "Hello World"})
print(result["result"]) # Output: "Processed: Hello World"
```
## Next Steps
Export OpenLit traces to Judgment for unified observability.
Monitor your Langgraph agents in production with behavioral scoring.
Learn more about Judgment's tracing capabilities and advanced configuration.